vLLM on Kubernetes: The Complete Deep Dive for Scalable LLM Inference
— vllm, kubernetes, llm, gpu, inference, ml-ops, distributed-systems, ai-infrastructure — 22 min read
You need to serve a 70B parameter model to thousands of users. Traditional serving would require 140GB of GPU memory per instance, making it economically unfeasible. Enter vLLM - a high-throughput inference engine that can serve the same model with 10x better throughput using revolutionary memory management techniques.
But running vLLM at scale requires more than just starting a server. You need orchestration, autoscaling, GPU scheduling, and observability. This is where Kubernetes becomes essential - transforming vLLM from a fast inference engine into a production-grade AI platform.
This deep dive explores vLLM's internals, optimization techniques, and most importantly, how to deploy and scale it on Kubernetes for production workloads.
Understanding vLLM Architecture
The Memory Problem in LLM Serving

Traditional LLM serving faces a critical bottleneck: memory fragmentation and inefficient KV cache management. When serving multiple requests, each needs to store attention keys and values for all previous tokens. This KV cache grows linearly with sequence length and batch size, quickly exhausting GPU memory.
Consider serving a 13B parameter model:
- Model weights: ~26GB (FP16)
- KV cache per token: ~800KB
- For 2048 tokens × 100 concurrent requests: ~160GB just for KV cache!
PagedAttention: The Core Innovation
vLLM's PagedAttention treats KV cache like virtual memory in operating systems. Instead of contiguous memory allocation, it uses paged blocks:
# Simplified PagedAttention conceptclass PagedAttention: def __init__(self, block_size=16, num_blocks=1000): self.block_size = block_size # tokens per block self.num_blocks = num_blocks self.gpu_blocks = [] # Physical blocks on GPU self.block_table = {} # Logical to physical mapping def allocate_blocks(self, sequence_id, num_tokens): """Allocate blocks for a sequence using paging""" num_blocks_needed = (num_tokens + self.block_size - 1) // self.block_size allocated_blocks = [] for _ in range(num_blocks_needed): # Find free block or evict if necessary block = self.get_free_block() if block is None: block = self.evict_block() # LRU eviction allocated_blocks.append(block) self.block_table[sequence_id] = allocated_blocks return allocated_blocks def attention(self, query, sequence_id): """Compute attention using paged KV cache""" blocks = self.block_table[sequence_id] # Gather KV cache from non-contiguous blocks keys = [] values = [] for block_id in blocks: block = self.gpu_blocks[block_id] keys.append(block.keys) values.append(block.values) # Compute attention with gathered KV cache return compute_attention(query, keys, values)This approach provides several benefits:
- Zero memory waste: Only allocated pages are used
- Dynamic sharing: Multiple sequences can share prompt cache
- Flexible scheduling: Sequences can be preempted and resumed
Continuous Batching
Traditional static batching waits for all sequences to complete before processing new ones. vLLM implements continuous batching:
class ContinuousBatchingScheduler: def __init__(self, max_batch_size=256): self.max_batch_size = max_batch_size self.running = [] # Currently processing self.waiting = [] # Waiting queue self.preempted = [] # Preempted sequences def schedule(self): """Schedule sequences for next iteration""" batch = [] # First, try to schedule running sequences for seq in self.running: if not seq.is_finished(): if self.can_allocate_blocks(seq): batch.append(seq) else: # Preempt if cannot allocate self.preempt(seq) # Fill remaining slots with waiting sequences while len(batch) < self.max_batch_size and self.waiting: seq = self.waiting.pop(0) if self.can_allocate_blocks(seq): batch.append(seq) self.running.append(seq) else: break # Try to schedule preempted sequences for seq in self.preempted[:]: if len(batch) >= self.max_batch_size: break if self.can_allocate_blocks(seq): batch.append(seq) self.preempted.remove(seq) self.running.append(seq) return batch def iteration(self, batch): """Process one iteration of generation""" # Generate next token for all sequences outputs = self.model.generate(batch) # Handle finished sequences for i, seq in enumerate(batch): seq.add_token(outputs[i]) if seq.is_finished(): self.running.remove(seq) self.free_blocks(seq) # Schedule next batch immediately return self.schedule()Tensor Parallelism
For models too large for a single GPU, vLLM implements tensor parallelism:
class TensorParallelLinear: """Tensor parallel linear layer""" def __init__(self, in_features, out_features, tp_size=1): self.tp_size = tp_size self.tp_rank = get_tensor_parallel_rank() # Partition weights across GPUs self.out_features_per_partition = out_features // tp_size self.weight = create_weight( in_features, self.out_features_per_partition ) def forward(self, input): # Each GPU computes partial output partial_output = torch.matmul(input, self.weight) # All-reduce across tensor parallel group if self.tp_size > 1: torch.distributed.all_reduce( partial_output, group=get_tensor_parallel_group() ) return partial_output
# Model parallelism configurationclass ParallelLLM: def __init__(self, model_name, tp_size=1, pp_size=1): self.tp_size = tp_size # Tensor parallelism self.pp_size = pp_size # Pipeline parallelism # Distribute layers across GPUs if tp_size > 1: self.replace_with_parallel_layers() if pp_size > 1: self.setup_pipeline_stages()vLLM on Kubernetes Architecture
System Architecture
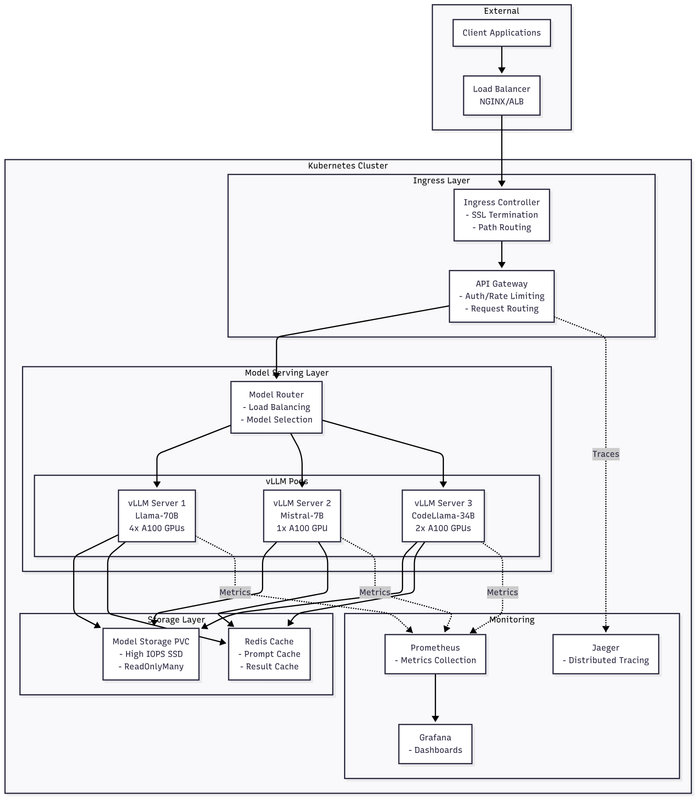 The production architecture consists of multiple layers:
The production architecture consists of multiple layers:
- Ingress Layer: Routes requests to appropriate model endpoints
- API Gateway: Handles authentication, rate limiting, and request routing
- vLLM Servers: Stateless inference servers with GPU resources
- Shared Storage: Model weights on high-performance storage (NVMe/SSD)
- Monitoring Stack: Prometheus, Grafana, and custom metrics
- Control Plane: Custom operators for model lifecycle management
Core Kubernetes Resources
vLLM Deployment with GPU Resources
apiVersion: apps/v1kind: Deploymentmetadata: name: vllm-llama-70b namespace: llm-servingspec: replicas: 3 selector: matchLabels: app: vllm model: llama-70b template: metadata: labels: app: vllm model: llama-70b annotations: prometheus.io/scrape: "true" prometheus.io/port: "8000" prometheus.io/path: "/metrics" spec: # GPU scheduling requirements nodeSelector: node.kubernetes.io/gpu: "true" nvidia.com/gpu.memory: "80gb" # A100 80GB # Tolerate GPU nodes tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule # Anti-affinity for HA affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: [vllm] topologyKey: kubernetes.io/hostname containers: - name: vllm image: vllm/vllm-openai:v0.3.0 command: ["python", "-m", "vllm.entrypoints.openai.api_server"] args: - --model=/models/llama-70b - --tensor-parallel-size=4 # 4-way tensor parallelism - --pipeline-parallel-size=1 - --max-model-len=4096 - --max-num-seqs=256 - --max-num-batched-tokens=32768 - --gpu-memory-utilization=0.95 - --enable-prefix-caching - --enforce-eager # Disable CUDA graphs for stability - --port=8000 - --host=0.0.0.0 ports: - containerPort: 8000 name: http protocol: TCP # Resource requirements resources: requests: memory: "200Gi" cpu: "16" nvidia.com/gpu: "4" # 4x A100 for tensor parallelism limits: memory: "220Gi" cpu: "32" nvidia.com/gpu: "4" # Environment configuration env: - name: CUDA_VISIBLE_DEVICES value: "0,1,2,3" - name: NCCL_DEBUG value: "INFO" - name: CUDA_LAUNCH_BLOCKING value: "0" - name: RAY_ADDRESS value: "ray://ray-head:10001" # For distributed inference - name: VLLM_WORKER_MULTIPROC_METHOD value: "spawn" # Volume mounts volumeMounts: - name: model-storage mountPath: /models readOnly: true - name: shm mountPath: /dev/shm - name: cache mountPath: /root/.cache # Health checks livenessProbe: httpGet: path: /health port: 8000 initialDelaySeconds: 300 # Model loading time periodSeconds: 30 timeoutSeconds: 10 failureThreshold: 3 readinessProbe: httpGet: path: /v1/models port: 8000 initialDelaySeconds: 300 periodSeconds: 10 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 3 # Startup probe for slow model loading startupProbe: httpGet: path: /health port: 8000 initialDelaySeconds: 60 periodSeconds: 30 timeoutSeconds: 10 failureThreshold: 20 # 10 minutes total # Init container for model download initContainers: - name: model-downloader image: python:3.10-slim command: ["/bin/bash", "-c"] args: - | if [ ! -d "/models/llama-70b" ]; then pip install huggingface-hub python -c " from huggingface_hub import snapshot_download snapshot_download( repo_id='meta-llama/Llama-2-70b-hf', local_dir='/models/llama-70b', token='${HF_TOKEN}' )" fi env: - name: HF_TOKEN valueFrom: secretKeyRef: name: huggingface-credentials key: token volumeMounts: - name: model-storage mountPath: /models volumes: # Shared memory for inter-process communication - name: shm emptyDir: medium: Memory sizeLimit: 64Gi # Model storage (PVC or hostPath) - name: model-storage persistentVolumeClaim: claimName: model-storage-pvc # Cache directory - name: cache emptyDir: sizeLimit: 50GiService and Ingress Configuration
apiVersion: v1kind: Servicemetadata: name: vllm-llama-70b namespace: llm-serving labels: app: vllm model: llama-70bspec: type: ClusterIP selector: app: vllm model: llama-70b ports: - port: 8000 targetPort: 8000 protocol: TCP name: http sessionAffinity: ClientIP # Sticky sessions for streaming sessionAffinityConfig: clientIP: timeoutSeconds: 3600
---apiVersion: networking.k8s.io/v1kind: Ingressmetadata: name: vllm-ingress namespace: llm-serving annotations: nginx.ingress.kubernetes.io/proxy-body-size: "50m" nginx.ingress.kubernetes.io/proxy-read-timeout: "300" nginx.ingress.kubernetes.io/proxy-send-timeout: "300" nginx.ingress.kubernetes.io/proxy-connect-timeout: "300" nginx.ingress.kubernetes.io/proxy-buffering: "off" # For streaming nginx.ingress.kubernetes.io/ssl-redirect: "true" cert-manager.io/cluster-issuer: letsencrypt-prod # Rate limiting nginx.ingress.kubernetes.io/limit-rps: "100" nginx.ingress.kubernetes.io/limit-connections: "10"spec: ingressClassName: nginx tls: - hosts: - llm.example.com secretName: llm-tls rules: - host: llm.example.com http: paths: - path: /v1/completions pathType: Prefix backend: service: name: vllm-llama-70b port: number: 8000 - path: /v1/chat/completions pathType: Prefix backend: service: name: vllm-llama-70b port: number: 8000Advanced Deployment Patterns
Multi-Model Serving with Model Router
When serving multiple models, we need intelligent routing based on model capabilities and load:
# model_router.py - Custom routing logicfrom typing import Dict, Listimport randomimport asynciofrom fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelimport httpx
app = FastAPI()
class ModelEndpoint: def __init__(self, name: str, url: str, capabilities: List[str], max_tokens: int, tps: float): self.name = name self.url = url self.capabilities = capabilities self.max_tokens = max_tokens self.tps = tps # Tokens per second self.current_load = 0 self.healthy = True
# Model registryMODELS = { "llama-70b": ModelEndpoint( name="llama-70b", url="http://vllm-llama-70b:8000", capabilities=["chat", "completion", "code"], max_tokens=4096, tps=50 ), "mistral-7b": ModelEndpoint( name="mistral-7b", url="http://vllm-mistral-7b:8000", capabilities=["chat", "completion"], max_tokens=8192, tps=150 ), "codellama-34b": ModelEndpoint( name="codellama-34b", url="http://vllm-codellama-34b:8000", capabilities=["code", "completion"], max_tokens=16384, tps=80 )}
class CompletionRequest(BaseModel): prompt: str max_tokens: int = 512 temperature: float = 0.7 model: str = None # Optional model preference capability: str = "chat" # Required capability
@app.post("/v1/completions")async def route_completion(request: CompletionRequest): """Route completion request to appropriate model""" # Find suitable models suitable_models = [] for model_name, endpoint in MODELS.items(): if request.capability in endpoint.capabilities: if not request.model or request.model == model_name: if endpoint.healthy and request.max_tokens <= endpoint.max_tokens: suitable_models.append(endpoint) if not suitable_models: raise HTTPException(status_code=503, detail="No suitable model available") # Select model based on load balancing selected = min(suitable_models, key=lambda m: m.current_load / m.tps) # Forward request selected.current_load += request.max_tokens try: async with httpx.AsyncClient(timeout=300) as client: response = await client.post( f"{selected.url}/v1/completions", json=request.dict() ) response.raise_for_status() return response.json() finally: selected.current_load -= request.max_tokens
@app.get("/health")async def health_check(): """Check health of all model endpoints""" health_status = {} async def check_model(name: str, endpoint: ModelEndpoint): try: async with httpx.AsyncClient(timeout=5) as client: response = await client.get(f"{endpoint.url}/health") endpoint.healthy = response.status_code == 200 health_status[name] = "healthy" if endpoint.healthy else "unhealthy" except: endpoint.healthy = False health_status[name] = "unreachable" tasks = [check_model(name, endpoint) for name, endpoint in MODELS.items()] await asyncio.gather(*tasks) return health_statusDeploy the model router:
apiVersion: apps/v1kind: Deploymentmetadata: name: model-router namespace: llm-servingspec: replicas: 3 selector: matchLabels: app: model-router template: metadata: labels: app: model-router spec: containers: - name: router image: llm-router:latest command: ["uvicorn", "model_router:app", "--host", "0.0.0.0", "--port", "8080"] ports: - containerPort: 8080 resources: requests: memory: "2Gi" cpu: "2" limits: memory: "4Gi" cpu: "4" env: - name: MODELS_CONFIG value: /config/models.yaml volumeMounts: - name: config mountPath: /config volumes: - name: config configMap: name: model-router-configHorizontal Pod Autoscaling with Custom Metrics
vLLM exposes metrics that are more relevant than CPU/memory for scaling decisions:
# Custom metrics for vLLM autoscalingapiVersion: v1kind: ConfigMapmetadata: name: vllm-metrics-config namespace: llm-servingdata: metrics.yaml: | # Metrics to expose for HPA metrics: - name: gpu_cache_usage_ratio query: | avg( vllm_gpu_cache_usage_perc{job="vllm-llama-70b"} ) - name: generation_throughput query: | sum( rate(vllm_generation_tokens_total{job="vllm-llama-70b"}[1m]) ) - name: request_latency_p99 query: | histogram_quantile(0.99, rate(vllm_request_duration_seconds_bucket{job="vllm-llama-70b"}[1m]) ) - name: pending_requests query: | sum( vllm_pending_requests{job="vllm-llama-70b"} )
---apiVersion: autoscaling/v2kind: HorizontalPodAutoscalermetadata: name: vllm-hpa namespace: llm-servingspec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: vllm-llama-70b minReplicas: 2 maxReplicas: 10 metrics: # Scale based on GPU cache usage - type: External external: metric: name: gpu_cache_usage_ratio selector: matchLabels: model: llama-70b target: type: Value value: "80" # Target 80% cache usage # Scale based on pending requests - type: External external: metric: name: pending_requests selector: matchLabels: model: llama-70b target: type: AverageValue averageValue: "50" # Max 50 pending per pod # Scale based on P99 latency - type: External external: metric: name: request_latency_p99 selector: matchLabels: model: llama-70b target: type: Value value: "10" # Target P99 < 10 seconds behavior: scaleDown: stabilizationWindowSeconds: 300 # Wait 5 minutes before scaling down policies: - type: Percent value: 50 # Scale down by max 50% periodSeconds: 60 scaleUp: stabilizationWindowSeconds: 60 policies: - type: Percent value: 100 # Double pods if needed periodSeconds: 60 - type: Pods value: 2 # Add max 2 pods at a time periodSeconds: 60Vertical Pod Autoscaling for Right-Sizing
VPA helps determine optimal resource allocation:
apiVersion: autoscaling.k8s.io/v1kind: VerticalPodAutoscalermetadata: name: vllm-vpa namespace: llm-servingspec: targetRef: apiVersion: apps/v1 kind: Deployment name: vllm-llama-70b updatePolicy: updateMode: "Off" # Only recommend, don't auto-update resourcePolicy: containerPolicies: - containerName: vllm minAllowed: cpu: "8" memory: "100Gi" maxAllowed: cpu: "64" memory: "400Gi" controlledResources: ["cpu", "memory"] # Don't touch GPU allocation controlledValues: RequestsOnlyGPU Scheduling and Optimization
GPU Node Configuration
Proper GPU node setup is crucial for vLLM performance:
# GPU node configuration with NVIDIA GPU OperatorapiVersion: v1kind: ConfigMapmetadata: name: gpu-node-config namespace: gpu-operatordata: nvidia-config.yaml: | # MIG (Multi-Instance GPU) configuration for A100 mig-config: - devices: all mig-enabled: false # Disable MIG for vLLM # DCGM exporter configuration dcgm-exporter: arguments: - -f - /etc/dcgm-exporter/dcp-metrics-included.csv # Time-slicing configuration (not recommended for vLLM) time-slicing: enabled: false # GPU feature discovery gpu-feature-discovery: sleepInterval: 60s configs: - name: "device-attributes" matchOn: - pciId: "0x20B2" # A100 40GB name: "A100-40GB" - pciId: "0x20B5" # A100 80GB name: "A100-80GB"
---# Device plugin configurationapiVersion: v1kind: ConfigMapmetadata: name: nvidia-device-plugin-config namespace: kube-systemdata: config.yaml: | version: v1 flags: migStrategy: "none" # Don't use MIG for vLLM failOnInitError: true nvidiaDriverRoot: "/" passDeviceSpecs: true deviceListStrategy: "envvar" deviceIDStrategy: "uuid" resources: - name: nvidia.com/gpu replicas: 1 # Don't virtualize GPUs sharing: timeSlicing: renameByDefault: false failRequestsGreaterThanOne: true # Prevent time-slicingGPU Affinity and NUMA Optimization
For optimal performance, align GPU, CPU, and memory:
apiVersion: apps/v1kind: DaemonSetmetadata: name: gpu-numa-optimizer namespace: kube-systemspec: selector: matchLabels: name: gpu-numa-optimizer template: metadata: labels: name: gpu-numa-optimizer spec: hostNetwork: true hostPID: true containers: - name: optimizer image: nvidia/cuda:12.0-base securityContext: privileged: true command: ["/bin/bash", "-c"] args: - | #!/bin/bash # Set CPU affinity for GPUs based on NUMA topology # Get GPU NUMA nodes for gpu in $(nvidia-smi -L | awk '{print $2}' | cut -d: -f1); do numa_node=$(nvidia-smi -i $gpu --query-gpu=numa_affinity --format=csv,noheader) # Set CPU governor to performance for cpu in $(numactl --hardware | grep "node $numa_node cpus" | cut -d: -f2); do echo performance > /sys/devices/system/cpu/cpu$cpu/cpufreq/scaling_governor done # Set IRQ affinity irq=$(cat /proc/interrupts | grep nvidia | awk '{print $1}' | tr -d :) echo $numa_node > /proc/irq/$irq/node done # Optimize PCIe settings setpci -s $(lspci | grep NVIDIA | awk '{print $1}') 68.w=5936 # Max read request # Set GPU persistence mode nvidia-smi -pm 1 # Set GPU performance mode nvidia-smi -ac 1593,1410 # A100 optimal clocks # Keep running sleep infinity volumeMounts: - name: sys mountPath: /sys - name: proc mountPath: /proc volumes: - name: sys hostPath: path: /sys - name: proc hostPath: path: /procGPU Scheduling Policies
Implement custom scheduling for GPU workloads:
// gpu_scheduler.go - Custom scheduler extenderpackage main
import ( "encoding/json" "fmt" "net/http" v1 "k8s.io/api/core/v1" "k8s.io/klog/v2" schedulerapi "k8s.io/kube-scheduler/extender/v1")
type GPUScheduler struct { // Track GPU usage across nodes nodeGPUUsage map[string]GPUInfo}
type GPUInfo struct { TotalGPUs int AvailableGPUs int GPUMemory int64 // in GB InterconnectType string // NVLink, PCIe}
// Filter nodes based on GPU requirementsfunc (s *GPUScheduler) Filter(args schedulerapi.ExtenderArgs) (*schedulerapi.ExtenderFilterResult, error) { pod := &args.Pod nodes := args.Nodes.Items // Extract GPU requirements from pod gpuRequest := getGPURequest(pod) if gpuRequest == 0 { // No GPU needed, pass all nodes return &schedulerapi.ExtenderFilterResult{ Nodes: args.Nodes, }, nil } // Check for tensor parallelism requirements tpSize := getTensorParallelSize(pod) filteredNodes := []v1.Node{} failedNodes := map[string]string{} for _, node := range nodes { nodeInfo := s.nodeGPUUsage[node.Name] // Check GPU availability if nodeInfo.AvailableGPUs < gpuRequest { failedNodes[node.Name] = fmt.Sprintf( "Insufficient GPUs: requested=%d, available=%d", gpuRequest, nodeInfo.AvailableGPUs) continue } // Check interconnect for tensor parallelism if tpSize > 1 && nodeInfo.InterconnectType != "NVLink" { failedNodes[node.Name] = "Tensor parallelism requires NVLink" continue } // Check GPU memory requirements requiredMemory := getGPUMemoryRequest(pod) if nodeInfo.GPUMemory < requiredMemory { failedNodes[node.Name] = fmt.Sprintf( "Insufficient GPU memory: requested=%dGB, available=%dGB", requiredMemory, nodeInfo.GPUMemory) continue } filteredNodes = append(filteredNodes, node) } return &schedulerapi.ExtenderFilterResult{ Nodes: &v1.NodeList{Items: filteredNodes}, FailedNodes: failedNodes, }, nil}
// Prioritize nodes for GPU workloadsfunc (s *GPUScheduler) Prioritize(args schedulerapi.ExtenderArgs) (*schedulerapi.HostPriorityList, error) { pod := &args.Pod nodes := args.Nodes.Items hostPriorities := make(schedulerapi.HostPriorityList, len(nodes)) for i, node := range nodes { priority := s.calculatePriority(pod, node) hostPriorities[i] = schedulerapi.HostPriority{ Host: node.Name, Score: priority, } } return &hostPriorities, nil}
func (s *GPUScheduler) calculatePriority(pod *v1.Pod, node v1.Node) int64 { nodeInfo := s.nodeGPUUsage[node.Name] score := int64(0) // Prefer nodes with NVLink for multi-GPU pods if getTensorParallelSize(pod) > 1 && nodeInfo.InterconnectType == "NVLink" { score += 50 } // Prefer nodes with more available GPUs (bin packing) score += int64(nodeInfo.AvailableGPUs * 10) // Prefer nodes with matching GPU memory requiredMemory := getGPUMemoryRequest(pod) if nodeInfo.GPUMemory == requiredMemory { score += 30 // Exact match bonus } return score}
func main() { scheduler := &GPUScheduler{ nodeGPUUsage: make(map[string]GPUInfo), } // Register HTTP handlers http.HandleFunc("/filter", scheduler.handleFilter) http.HandleFunc("/prioritize", scheduler.handlePrioritize) klog.Info("Starting GPU scheduler extender on :8888") http.ListenAndServe(":8888", nil)}Monitoring and Observability
vLLM Metrics Collection
vLLM exposes detailed metrics for monitoring:
# vllm_exporter.py - Prometheus exporter for vLLM metricsfrom prometheus_client import start_http_server, Gauge, Counter, Histogramimport asyncioimport httpximport time
# Define metricsgpu_cache_usage = Gauge('vllm_gpu_cache_usage_perc', 'GPU KV cache usage percentage', ['model'])num_requests = Gauge('vllm_pending_requests', 'Number of pending requests', ['model'])generation_tokens = Counter('vllm_generation_tokens_total', 'Total generated tokens', ['model'])request_duration = Histogram('vllm_request_duration_seconds', 'Request duration in seconds', ['model'], buckets=(0.1, 0.5, 1, 2, 5, 10, 30, 60, 120))model_loaded = Gauge('vllm_model_loaded', 'Model loading status', ['model'])batch_size = Gauge('vllm_current_batch_size', 'Current batch size', ['model'])
async def collect_metrics(endpoint: str, model_name: str): """Collect metrics from vLLM server""" async with httpx.AsyncClient() as client: try: # Get server stats response = await client.get(f"{endpoint}/stats") stats = response.json() # Update metrics gpu_cache_usage.labels(model=model_name).set( stats.get('gpu_cache_usage', 0)) num_requests.labels(model=model_name).set( stats.get('num_pending_requests', 0)) batch_size.labels(model=model_name).set( stats.get('batch_size', 0)) # Check model status models_response = await client.get(f"{endpoint}/v1/models") if models_response.status_code == 200: model_loaded.labels(model=model_name).set(1) else: model_loaded.labels(model=model_name).set(0) except Exception as e: print(f"Error collecting metrics: {e}") model_loaded.labels(model=model_name).set(0)
async def main(): # Start Prometheus HTTP server start_http_server(8001) endpoints = [ ("http://vllm-llama-70b:8000", "llama-70b"), ("http://vllm-mistral-7b:8000", "mistral-7b"), ] while True: tasks = [collect_metrics(endpoint, model) for endpoint, model in endpoints] await asyncio.gather(*tasks) await asyncio.sleep(10) # Collect every 10 seconds
if __name__ == "__main__": asyncio.run(main())Grafana Dashboard Configuration
{ "dashboard": { "title": "vLLM Performance Dashboard", "panels": [ { "title": "Request Throughput", "targets": [ { "expr": "sum(rate(vllm_generation_tokens_total[5m])) by (model)", "legendFormat": "{{model}}" } ], "type": "graph" }, { "title": "GPU Cache Usage", "targets": [ { "expr": "vllm_gpu_cache_usage_perc", "legendFormat": "{{model}}" } ], "type": "gauge", "options": { "max": 100, "thresholds": { "steps": [ {"value": 0, "color": "green"}, {"value": 80, "color": "yellow"}, {"value": 95, "color": "red"} ] } } }, { "title": "Request Latency P99", "targets": [ { "expr": "histogram_quantile(0.99, rate(vllm_request_duration_seconds_bucket[5m]))", "legendFormat": "{{model}}" } ], "type": "graph" }, { "title": "Batch Size", "targets": [ { "expr": "vllm_current_batch_size", "legendFormat": "{{model}}" } ], "type": "graph" }, { "title": "GPU Memory Usage", "targets": [ { "expr": "DCGM_FI_DEV_FB_USED / DCGM_FI_DEV_FB_TOTAL * 100", "legendFormat": "GPU {{gpu}}" } ], "type": "graph" }, { "title": "GPU Utilization", "targets": [ { "expr": "DCGM_FI_DEV_GPU_UTIL", "legendFormat": "GPU {{gpu}}" } ], "type": "graph" } ] }}Distributed Tracing with OpenTelemetry
# vllm_tracing.py - OpenTelemetry integrationfrom opentelemetry import tracefrom opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporterfrom opentelemetry.sdk.trace import TracerProviderfrom opentelemetry.sdk.trace.export import BatchSpanProcessorfrom opentelemetry.instrumentation.fastapi import FastAPIInstrumentorimport time
# Configure tracingtrace.set_tracer_provider(TracerProvider())tracer = trace.get_tracer(__name__)
# Configure OTLP exporterotlp_exporter = OTLPSpanExporter( endpoint="otel-collector:4317", insecure=True,)
# Add span processorspan_processor = BatchSpanProcessor(otlp_exporter)trace.get_tracer_provider().add_span_processor(span_processor)
class TracedvLLMEngine: """Wrapper for vLLM engine with tracing""" def __init__(self, engine): self.engine = engine async def generate(self, request): with tracer.start_as_current_span("vllm.generate") as span: # Add request attributes span.set_attribute("model", self.engine.model_name) span.set_attribute("prompt_tokens", len(request.prompt.split())) span.set_attribute("max_tokens", request.max_tokens) span.set_attribute("temperature", request.temperature) # Tokenization phase with tracer.start_as_current_span("vllm.tokenize"): tokens = self.engine.tokenize(request.prompt) span.set_attribute("input_tokens", len(tokens)) # Scheduling phase with tracer.start_as_current_span("vllm.schedule"): batch = self.engine.scheduler.schedule() span.set_attribute("batch_size", len(batch)) # Generation phase with tracer.start_as_current_span("vllm.inference"): start_time = time.time() response = await self.engine.generate_internal(request) generation_time = time.time() - start_time span.set_attribute("generation_time", generation_time) span.set_attribute("output_tokens", len(response.tokens)) span.set_attribute("tokens_per_second", len(response.tokens) / generation_time) return responseProduction Best Practices
Model Optimization
Quantization for Memory Efficiency
# quantize_model.py - Quantize model for deploymentimport torchfrom transformers import AutoModelForCausalLM, AutoTokenizerfrom auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
def quantize_model(model_name: str, output_dir: str, bits: int = 4): """Quantize model using GPTQ""" # Load model and tokenizer model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(model_name) # Prepare calibration dataset calibration_dataset = load_calibration_data() # Configure quantization quantize_config = BaseQuantizeConfig( bits=bits, # 4-bit quantization group_size=128, desc_act=False, model_name_or_path=model_name ) # Quantize model print("Starting quantization...") model = AutoGPTQForCausalLM.from_pretrained( model_name, quantize_config=quantize_config ) model.quantize(calibration_dataset) # Save quantized model model.save_quantized(output_dir) tokenizer.save_pretrained(output_dir) print(f"Quantized model saved to {output_dir}") # Calculate compression ratio original_size = calculate_model_size(model_name) quantized_size = calculate_model_size(output_dir) compression_ratio = original_size / quantized_size print(f"Compression ratio: {compression_ratio:.2f}x") print(f"Memory saved: {(original_size - quantized_size) / 1e9:.2f} GB")Model Sharding Strategy
# Model sharding configurationapiVersion: v1kind: ConfigMapmetadata: name: model-sharding-config namespace: llm-servingdata: sharding.yaml: | models: llama-70b: tensor_parallel_size: 4 pipeline_parallel_size: 2 sequence_parallel: true cpu_offload: false # Layer distribution for pipeline parallelism pipeline_stages: - device: 0 layers: [0, 19] # First 20 layers - device: 1 layers: [20, 39] # Next 20 layers - device: 2 layers: [40, 59] # Next 20 layers - device: 3 layers: [60, 79] # Last 20 layers # Attention head distribution for tensor parallelism attention_heads_per_gpu: 16 # 64 total heads / 4 GPUs mistral-7b: tensor_parallel_size: 1 # Single GPU is enough pipeline_parallel_size: 1 sequence_parallel: false cpu_offload: falseHigh Availability Setup
# PodDisruptionBudget for high availabilityapiVersion: policy/v1kind: PodDisruptionBudgetmetadata: name: vllm-pdb namespace: llm-servingspec: minAvailable: 2 selector: matchLabels: app: vllm unhealthyPodEvictionPolicy: IfHealthyBudget
---# Anti-affinity for spreading across zonesapiVersion: apps/v1kind: Deploymentmetadata: name: vllm-ha namespace: llm-servingspec: replicas: 3 strategy: type: RollingUpdate rollingUpdate: maxSurge: 1 maxUnavailable: 0 # Zero downtime deployment template: spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app: vllm - maxSkew: 1 topologyKey: kubernetes.io/hostname whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: vllmRequest Batching and Queuing
# batch_processor.py - Intelligent request batchingimport asynciofrom typing import List, Dictimport timefrom dataclasses import dataclass
@dataclassclass Request: id: str prompt: str max_tokens: int timestamp: float priority: int = 0
class BatchProcessor: def __init__(self, max_batch_size: int = 256, max_wait_time: float = 0.1): self.max_batch_size = max_batch_size self.max_wait_time = max_wait_time self.pending_requests: List[Request] = [] self.processing = False async def add_request(self, request: Request) -> str: """Add request to batch queue""" self.pending_requests.append(request) # Start batch processing if not running if not self.processing: asyncio.create_task(self.process_batch()) # Wait for result return await self.wait_for_result(request.id) async def process_batch(self): """Process accumulated requests as batch""" self.processing = True while self.pending_requests: # Wait for batch to accumulate or timeout start_time = time.time() while (len(self.pending_requests) < self.max_batch_size and time.time() - start_time < self.max_wait_time and self.pending_requests): await asyncio.sleep(0.001) # Extract batch batch_size = min(len(self.pending_requests), self.max_batch_size) batch = self.pending_requests[:batch_size] self.pending_requests = self.pending_requests[batch_size:] # Sort by priority and timestamp batch.sort(key=lambda r: (-r.priority, r.timestamp)) # Process batch await self.process_requests(batch) self.processing = False async def process_requests(self, batch: List[Request]): """Send batch to vLLM for processing""" # Prepare batch request prompts = [r.prompt for r in batch] max_tokens = [r.max_tokens for r in batch] # Call vLLM results = await self.vllm_client.generate_batch( prompts=prompts, max_tokens=max_tokens ) # Store results for retrieval for request, result in zip(batch, results): self.results[request.id] = resultCost Optimization Strategies
# Spot instance configuration for cost savingsapiVersion: v1kind: ConfigMapmetadata: name: spot-instance-config namespace: llm-servingdata: nodeSelector: | node.kubernetes.io/instance-type: "p4d.24xlarge" karpenter.sh/capacity-type: "spot" tolerations: | - key: "karpenter.sh/spot" operator: "Equal" value: "true" effect: "NoSchedule" - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" # Graceful shutdown on spot termination preStop: | exec: command: - /bin/sh - -c - | # Drain connections gracefully kill -TERM 1 # Wait for ongoing requests sleep 30 # Force kill if still running kill -KILL 1
---# Karpenter provisioner for spot GPU instancesapiVersion: karpenter.sh/v1alpha5kind: Provisionermetadata: name: gpu-spot-provisionerspec: requirements: - key: karpenter.sh/capacity-type operator: In values: ["spot", "on-demand"] - key: kubernetes.io/arch operator: In values: ["amd64"] - key: node.kubernetes.io/instance-type operator: In values: - p4d.24xlarge # 8x A100 40GB - p4de.24xlarge # 8x A100 80GB - p3.8xlarge # 4x V100 16GB (cheaper) limits: resources: cpu: 10000 nvidia.com/gpu: 100 # Prefer spot, fallback to on-demand consolidation: enabled: true # Terminate empty nodes quickly ttlSecondsAfterEmpty: 30 # Spot interruption handling providerRef: name: gpu-nodepool userData: | #!/bin/bash # Install NVIDIA drivers apt-get update apt-get install -y nvidia-driver-525 # Configure GPU nvidia-smi -pm 1 nvidia-smi -ac 1593,1410 # Setup spot termination handler aws ec2 monitor-instances --instance-ids $(ec2-metadata --instance-id)Troubleshooting Guide
Common Issues and Solutions
Out of Memory (OOM) Errors
# Debug OOM issuesapiVersion: v1kind: Podmetadata: name: vllm-debugspec: containers: - name: debug image: vllm/vllm-openai:latest command: ["python"] args: - -c - | import torch import psutil import GPUtil # Check available memory print(f"System RAM: {psutil.virtual_memory().available / 1e9:.2f} GB") # Check GPU memory gpus = GPUtil.getGPUs() for gpu in gpus: print(f"GPU {gpu.id}: {gpu.memoryFree:.2f} MB free") # Estimate model memory requirements model_params = 70e9 # 70B parameters bytes_per_param = 2 # FP16 model_memory = model_params * bytes_per_param / 1e9 print(f"Model memory: {model_memory:.2f} GB") # KV cache estimation batch_size = 256 seq_length = 4096 hidden_size = 8192 num_layers = 80 kv_cache_memory = (batch_size * seq_length * hidden_size * num_layers * 2 * 2) / 1e9 print(f"KV cache memory: {kv_cache_memory:.2f} GB")Slow Generation Speed
# profiling.py - Profile vLLM performanceimport cProfileimport pstatsimport iofrom vllm import LLM, SamplingParams
def profile_generation(): # Initialize model llm = LLM( model="meta-llama/Llama-2-7b-hf", tensor_parallel_size=1, gpu_memory_utilization=0.9, ) # Test prompts prompts = ["Hello, how are you?"] * 100 sampling_params = SamplingParams( temperature=0.8, max_tokens=100, ) # Profile generation pr = cProfile.Profile() pr.enable() outputs = llm.generate(prompts, sampling_params) pr.disable() # Print statistics s = io.StringIO() ps = pstats.Stats(pr, stream=s).sort_stats('cumulative') ps.print_stats(20) print(s.getvalue()) # Calculate metrics total_tokens = sum(len(o.outputs[0].token_ids) for o in outputs) print(f"Total tokens generated: {total_tokens}") print(f"Tokens per second: {total_tokens / ps.total_tt:.2f}")
if __name__ == "__main__": profile_generation()NCCL Communication Errors
#!/bin/bash# debug_nccl.sh - Debug NCCL issues
# Check NCCL topologynvidia-smi topo -m
# Test NCCL communication/opt/nccl_tests/build/all_reduce_perf -b 8 -e 256M -f 2 -g 4
# Check InfiniBand (if available)ibstatibping -G <remote_gid>
# Environment variables for debuggingexport NCCL_DEBUG=INFOexport NCCL_DEBUG_SUBSYS=ALLexport NCCL_TREE_THRESHOLD=0export CUDA_VISIBLE_DEVICES=0,1,2,3
# Test with simple PyTorch distributedpython -c "import torchimport torch.distributed as dist
dist.init_process_group(backend='nccl')rank = dist.get_rank()tensor = torch.ones(1).cuda(rank)dist.all_reduce(tensor)print(f'Rank {rank}: {tensor.item()}')"Conclusion
Running vLLM on Kubernetes transforms LLM inference from an experimental setup to a production-grade platform. The combination of vLLM's memory optimizations (PagedAttention, continuous batching) with Kubernetes' orchestration capabilities (autoscaling, GPU scheduling, high availability) creates a robust inference infrastructure.
Key takeaways:
- Memory is the bottleneck: PagedAttention and proper GPU memory management are crucial
- Scheduling matters: Custom GPU scheduling ensures optimal hardware utilization
- Monitoring is essential: Track GPU cache usage and generation throughput, not just CPU/memory
- Cost optimization: Use spot instances and right-sizing to reduce costs by 70%+
- High availability: Implement proper health checks, PDBs, and anti-affinity rules
The architecture patterns shown here scale from single model deployments to multi-model, multi-region inference platforms serving millions of requests daily.
For production deployments, consider managed solutions like Amazon SageMaker, Google Vertex AI, or Azure ML which provide additional enterprise features while still leveraging vLLM under the hood.