Kubernetes Architecture: The Complete Deep Dive for Platform Engineers
— kubernetes, architecture, distributed-systems, containers, cloud-native, platform-engineering — 40 min read
You deploy a pod with kubectl apply. Within seconds, containers are running on nodes thousands of miles away. But what really happens in those seconds? How does a YAML file become running containers? How do 50,000 pods coordinate across 5,000 nodes without collision?
This is the definitive deep dive into Kubernetes architecture - not just what the components are, but how they truly work, their failure modes, and the distributed systems principles that make Kubernetes resilient at scale.
High-Level Architecture Overview
Complete Kubernetes Architecture
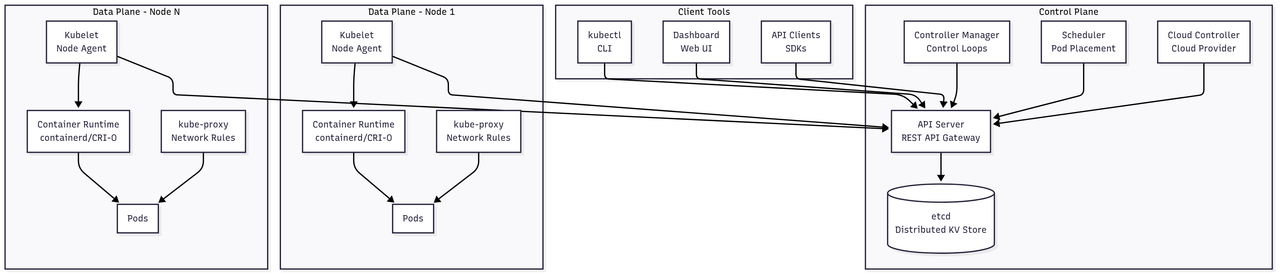
The architecture consists of:
- Control Plane: etcd, API Server, Controller Manager, Scheduler, Cloud Controller
- Data Plane: Kubelet, kube-proxy, Container Runtime on each node
- Client Tools: kubectl, Dashboard, API clients
Control Flow: Pod Creation
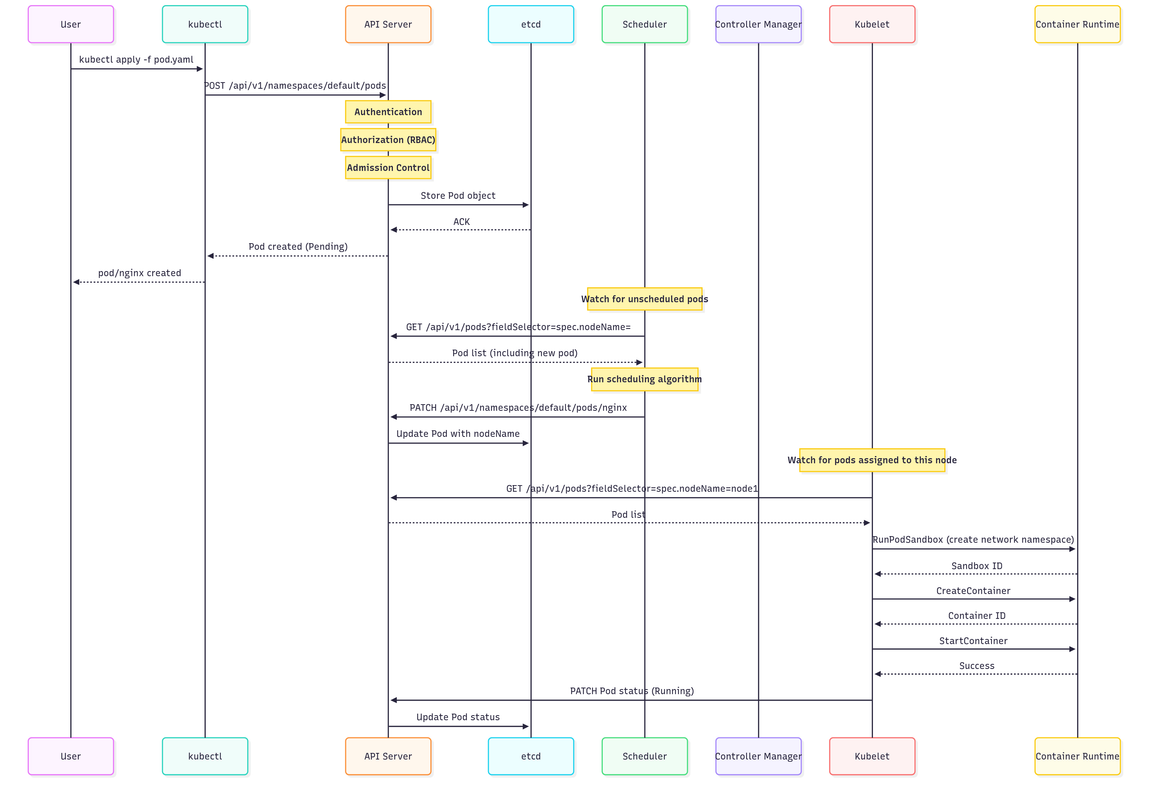
The pod creation flow involves:
- kubectl submits pod manifest to API Server
- API Server validates and stores in etcd
- Scheduler watches for unscheduled pods and assigns to node
- Kubelet on assigned node pulls image and creates containers
- Container Runtime starts the containers
- Kubelet updates pod status back to API Server
The Distributed Systems Foundation
CAP Theorem in Kubernetes
Kubernetes makes specific trade-offs in the CAP theorem:
Consistency + Partition Tolerance (CP System)├── etcd: Strongly consistent via Raft├── API Server: Linearizable reads/writes└── Eventually Consistent Views: ├── Kubelet → API Server (heartbeats) ├── Controllers → API Server (reconciliation) └── Scheduler → API Server (binding)During network partitions:
- etcd maintains consistency, may become unavailable
- API Server rejects writes if can't reach etcd quorum
- Kubelets continue running existing pods (availability)
- Controllers queue changes for later reconciliation
The Reconciliation Pattern
Kubernetes' genius is the reconciliation loop - a fundamental pattern that drives the entire system toward the desired state. This pattern is used by every controller, operator, and even the kubelet itself. It's what makes Kubernetes self-healing and eventually consistent.
The reconciliation loop continuously compares the desired state (stored in etcd) with the actual state (reality in the cluster) and takes actions to converge them:
// The universal pattern used everywhere in Kubernetesfor { desired := getDesiredState() // From etcd via API server actual := getActualState() // From cluster reality diff := compareStates(desired, actual) if diff != nil { makeChanges(diff) // Drive actual → desired } sleep(reconciliationInterval)}This pattern provides:
- Idempotency: Safe to run repeatedly
- Self-healing: Automatically fixes drift
- Eventual consistency: Converges over time
- Failure tolerance: Resumes after crashes
Control Plane Deep Dive
Control Plane Component Interactions
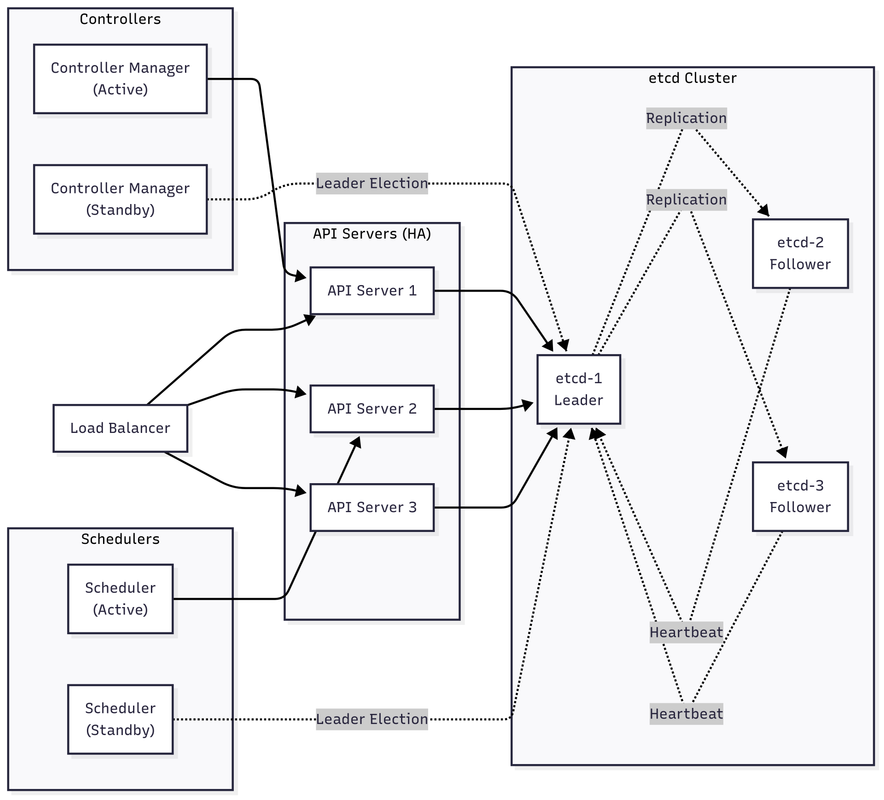
In a highly available setup:
- etcd cluster runs with 3 or 5 nodes using Raft consensus
- Multiple API servers behind a load balancer for redundancy
- Controller Manager and Scheduler use leader election (only one active)
- All components watch and update state through the API server
etcd: The Source of Truth
etcd is a distributed key-value store using Raft consensus protocol to maintain strong consistency across the cluster. It stores the entire cluster state - every pod, service, secret, and config map. Without etcd, Kubernetes has no memory.
Kubernetes stores all objects in etcd with a hierarchical key structure. The API server is the only component that directly communicates with etcd, providing a consistent interface and abstraction layer:
// How Kubernetes uses etcdtype EtcdStorage struct { client *clientv3.Client codec runtime.Codec}
// All Kubernetes objects stored with structure:// /registry/{resource}/{namespace}/{name}//// Examples:// /registry/pods/default/nginx// /registry/services/kube-system/kube-dns// /registry/nodes/worker-1
// Create stores a new object in etcd using a conditional transaction// This ensures the object doesn't already exist, preventing accidental overwritesfunc (e *EtcdStorage) Create(ctx context.Context, key string, obj runtime.Object) error { data, err := e.codec.Encode(obj) if err != nil { return err } // Conditional put - fails if key exists txn := e.client.Txn(ctx). If(clientv3.Compare(clientv3.Version(key), "=", 0)). Then(clientv3.OpPut(key, string(data))) resp, err := txn.Commit() if !resp.Succeeded { return errors.New("object already exists") } return err}
// Watch creates a watch stream for changes to objects under a key prefix// The revision parameter allows resuming watches after disconnectionfunc (e *EtcdStorage) Watch(ctx context.Context, key string, revision int64) watch.Interface { watcher := e.client.Watch(ctx, key, clientv3.WithPrefix(), // Watch all keys with prefix clientv3.WithRev(revision), // Start from specific revision clientv3.WithProgressNotify()) return &etcdWatcher{ ctx: ctx, watcher: watcher, codec: e.codec, }}Raft Consensus in etcd
Raft ensures that etcd remains consistent even during network partitions and node failures. It works by electing a leader that handles all write requests, replicating them to followers. If the leader fails, followers elect a new leader, ensuring the cluster continues operating.
Here's a simplified implementation showing the core concepts of leader election and log replication:
# Simplified Raft implementationclass RaftNode: def __init__(self, node_id, peers): self.node_id = node_id self.peers = peers self.state = "FOLLOWER" self.current_term = 0 self.voted_for = None self.log = [] self.commit_index = 0 def request_vote(self, term, candidate_id, last_log_index, last_log_term): if term < self.current_term: return False if term > self.current_term: self.current_term = term self.voted_for = None self.state = "FOLLOWER" # Grant vote if haven't voted and candidate's log is up-to-date if (self.voted_for is None or self.voted_for == candidate_id) and \ self.is_log_up_to_date(last_log_index, last_log_term): self.voted_for = candidate_id return True return False def append_entries(self, term, leader_id, prev_log_index, prev_log_term, entries, leader_commit): if term < self.current_term: return False self.current_term = term self.state = "FOLLOWER" self.reset_election_timeout() # Check log consistency if prev_log_index > 0: if len(self.log) < prev_log_index or \ self.log[prev_log_index-1].term != prev_log_term: return False # Append new entries self.log = self.log[:prev_log_index] + entries # Update commit index if leader_commit > self.commit_index: self.commit_index = min(leader_commit, len(self.log)) return Trueetcd Performance Tuning
Production etcd clusters require careful tuning for reliability and performance. Key considerations include separating the write-ahead log (WAL) to different disks, setting appropriate quotas to prevent disk exhaustion, and tuning heartbeat intervals based on network latency.
This configuration demonstrates best practices for a production etcd cluster:
# etcd configuration for productionname: etcd-server-1data-dir: /var/lib/etcdwal-dir: /var/lib/etcd-wal # Separate WAL for performance
# Cluster configurationinitial-cluster: etcd-1=https://10.0.1.10:2380,etcd-2=https://10.0.1.11:2380,etcd-3=https://10.0.1.12:2380initial-cluster-state: newinitial-cluster-token: etcd-cluster-token
# Client/Peer URLslisten-client-urls: https://0.0.0.0:2379advertise-client-urls: https://10.0.1.10:2379listen-peer-urls: https://0.0.0.0:2380initial-advertise-peer-urls: https://10.0.1.10:2380
# Performance tuningquota-backend-bytes: 8589934592 # 8GBauto-compaction-retention: 1hsnapshot-count: 10000heartbeat-interval: 100election-timeout: 1000
# Securityclient-transport-security: cert-file: /etc/etcd/pki/server.crt key-file: /etc/etcd/pki/server.key client-cert-auth: true trusted-ca-file: /etc/etcd/pki/ca.crt
peer-transport-security: cert-file: /etc/etcd/pki/peer.crt key-file: /etc/etcd/pki/peer.key client-cert-auth: true trusted-ca-file: /etc/etcd/pki/ca.crtAPI Server: The Gateway
API Server Request Flow

The API server processes requests through multiple stages:
- Authentication: Verify who you are (X.509, tokens, OIDC)
- Authorization: Check what you can do (RBAC, ABAC)
- Admission Control: Mutate and validate the request
- Schema Validation: Ensure request conforms to API schema
- Storage: Persist to etcd
- Response: Return result and trigger watches
The API server acts as the gateway to the cluster, processing every kubectl command, controller action, and scheduler decision. It validates, authorizes, and persists all changes to etcd. Understanding its request flow is crucial for debugging permission issues and understanding latency.
Here's how the API server processes each request through multiple stages of validation and authorization:
// API Server request flowtype APIServer struct { storage StorageInterface admissions []AdmissionPlugin authorizer Authorizer audit AuditLogger}
// HandleRequest processes an API request through the full pipeline:// authentication -> authorization -> admission -> validation -> storage// Any stage can reject the request, ensuring defense in depthfunc (s *APIServer) HandleRequest(w http.ResponseWriter, r *http.Request) { // 1. Authentication user, err := s.authenticateRequest(r) if err != nil { http.Error(w, "Unauthorized", 401) return } // 2. Audit logging (request stage) s.audit.LogRequest(user, r) // 3. Parse API request gvr, namespace, name := s.parseRequest(r) verb := s.getVerb(r.Method) // 4. Authorization decision := s.authorizer.Authorize(user, verb, gvr, namespace, name) if !decision.Allowed { http.Error(w, "Forbidden", 403) return } // 5. Admission control (mutating) obj, err := s.decodeBody(r) for _, plugin := range s.mutatingAdmissions { obj, err = plugin.Admit(obj, user) if err != nil { http.Error(w, err.Error(), 400) return } } // 6. Admission control (validating) for _, plugin := range s.validatingAdmissions { if err := plugin.Validate(obj, user); err != nil { http.Error(w, err.Error(), 400) return } } // 7. Storage operation result, err := s.executeStorage(verb, gvr, namespace, name, obj) if err != nil { http.Error(w, err.Error(), 500) return } // 8. Response s.writeResponse(w, result) // 9. Audit logging (response stage) s.audit.LogResponse(user, r, result)}API Machinery: How Objects Work
The API machinery defines how Kubernetes objects are structured, validated, and stored. Every resource in Kubernetes - from Pods to Custom Resources - follows the same patterns. This consistency enables powerful abstractions like kubectl, client libraries, and operators to work uniformly across all resource types.
The type system ensures that all objects have consistent metadata and can be processed by generic controllers:
// Every Kubernetes object implements this interfacetype Object interface { GetObjectKind() schema.ObjectKind DeepCopyObject() Object}
// TypeMeta identifies the API version and kindtype TypeMeta struct { APIVersion string `json:"apiVersion"` Kind string `json:"kind"`}
// ObjectMeta contains all metadatatype ObjectMeta struct { Name string `json:"name"` Namespace string `json:"namespace,omitempty"` UID types.UID `json:"uid,omitempty"` ResourceVersion string `json:"resourceVersion,omitempty"` Generation int64 `json:"generation,omitempty"` CreationTimestamp Time `json:"creationTimestamp,omitempty"` DeletionTimestamp *Time `json:"deletionTimestamp,omitempty"` Labels map[string]string `json:"labels,omitempty"` Annotations map[string]string `json:"annotations,omitempty"` OwnerReferences []OwnerReference `json:"ownerReferences,omitempty"` Finalizers []string `json:"finalizers,omitempty"`}
// Example: How a Pod is structuredtype Pod struct { TypeMeta `json:",inline"` ObjectMeta `json:"metadata,omitempty"` Spec PodSpec `json:"spec,omitempty"` Status PodStatus `json:"status,omitempty"`}OpenAPI and Discovery
Kubernetes exposes its API schema through OpenAPI (formerly Swagger), enabling dynamic discovery of resources and their capabilities. This is how kubectl knows what resources are available, what fields they support, and what operations are allowed. It's also how tools like kubectl explain and API documentation are generated.
The discovery client queries the API server to learn about available resources:
// How kubectl knows what resources existtype DiscoveryClient struct { client RESTClient}
func (d *DiscoveryClient) ServerResourcesForGroupVersion(groupVersion string) (*APIResourceList, error) { // GET /apis/{group}/{version} result := &APIResourceList{} err := d.client.Get(). AbsPath("/apis", groupVersion). Do(). Into(result) return result, err}
// Returns something like:// {// "kind": "APIResourceList",// "groupVersion": "apps/v1",// "resources": [// {// "name": "deployments",// "singularName": "deployment",// "namespaced": true,// "kind": "Deployment",// "verbs": ["create", "delete", "get", "list", "patch", "update", "watch"],// "shortNames": ["deploy"],// "categories": ["all"]// }// ]// }Controller Manager: The Orchestrator
Controller Pattern

The controller pattern follows a continuous reconciliation loop:
- Watch: Monitor API server for resource changes
- Queue: Add changed items to work queue
- Process: Dequeue and process items
- Compare: Check desired state vs actual state
- Act: Create, update, or delete resources to match desired state
- Update: Report status back to API server
Controllers are the brain of Kubernetes, implementing the control loops that drive the cluster toward the desired state. Each controller watches specific resources and takes action when they change. The controller pattern is so fundamental that Kubernetes provides frameworks to build custom controllers easily.
This generic pattern shows how controllers use informers for efficient watching and work queues for reliable processing:
// Generic controller patterntype Controller struct { name string informer cache.SharedInformer workqueue workqueue.RateLimitingInterface client kubernetes.Interface}
// Run starts the controller's main loop, including informers and workers// It waits for cache sync before processing to ensure a consistent viewfunc (c *Controller) Run(stopCh <-chan struct{}) { // Start informer to watch resources go c.informer.Run(stopCh) // Wait for cache sync if !cache.WaitForCacheSync(stopCh, c.informer.HasSynced) { return } // Start workers for i := 0; i < c.workers; i++ { go wait.Until(c.runWorker, time.Second, stopCh) } <-stopCh}
func (c *Controller) runWorker() { for c.processNextWorkItem() { }}
// processNextWorkItem dequeues and processes a single item from the work queue// It handles retries with exponential backoff for transient failuresfunc (c *Controller) processNextWorkItem() bool { key, quit := c.workqueue.Get() if quit { return false } defer c.workqueue.Done(key) err := c.syncHandler(key.(string)) c.handleErr(err, key) return true}
// syncDeployment reconciles a Deployment with its ReplicaSets and Pods// It implements the core logic for rolling updates and rollbackfunc (dc *DeploymentController) syncDeployment(key string) error { namespace, name, _ := cache.SplitMetaNamespaceKey(key) deployment, err := dc.deploymentLister.Deployments(namespace).Get(name) if err != nil { return err } // List ReplicaSets owned by this Deployment replicaSets, err := dc.getReplicaSetsForDeployment(deployment) if err != nil { return err } // Separate active/old ReplicaSets newRS, oldRSs := dc.getAllReplicaSetsAndSyncRevision(deployment, replicaSets) // Scale up/down based on strategy switch deployment.Spec.Strategy.Type { case apps.RecreateDeploymentStrategyType: return dc.rolloutRecreate(deployment, newRS, oldRSs) case apps.RollingUpdateDeploymentStrategyType: return dc.rolloutRolling(deployment, newRS, oldRSs) } return nil}Built-in Controllers
Kubernetes includes dozens of built-in controllers, each responsible for a specific resource type. Understanding their responsibilities helps debug issues and understand the cascade of events when you create resources. For example, creating a Deployment triggers the Deployment controller, which creates a ReplicaSet, which triggers the ReplicaSet controller, which creates Pods.
Here's a map of the major controllers and what they manage:
# Major controllers and their responsibilitiescontrollers: deployment: watches: [Deployment, ReplicaSet, Pod] manages: ReplicaSet ensures: Deployment spec → ReplicaSet reality replicaset: watches: [ReplicaSet, Pod] manages: Pod ensures: Desired replicas === Running pods statefulset: watches: [StatefulSet, Pod, PVC] manages: [Pod, PVC] ensures: Ordered, persistent pod identity daemonset: watches: [DaemonSet, Pod, Node] manages: Pod ensures: One pod per node job: watches: [Job, Pod] manages: Pod ensures: Run to completion cronjob: watches: [CronJob, Job] manages: Job ensures: Scheduled job creation service: watches: [Service, Pod, Endpoints] manages: Endpoints ensures: Service → Pod mapping endpoint: watches: [Service, Pod] manages: Endpoints ensures: Healthy pod IPs in endpoints namespace: watches: [Namespace] manages: Namespace finalization ensures: Clean namespace deletion gc: watches: [All resources] manages: Orphaned resources ensures: Owner reference integrityScheduler: The Brain
Scheduling Pipeline

The scheduler uses a two-phase pipeline:
Scheduling Cycle:
- Filter out nodes that don't meet requirements
- Score remaining nodes based on various factors
- Select the best node
Binding Cycle:
- Reserve resources on selected node
- Perform pre-binding tasks (volumes, etc.)
- Bind pod to node via API server
The scheduler makes placement decisions for every pod, considering resource requirements, affinity rules, taints, and dozens of other factors. It must make these decisions quickly (milliseconds) even in clusters with thousands of nodes. The scheduler uses a plugin architecture allowing custom scheduling logic.
This simplified algorithm shows the two-phase approach: filtering feasible nodes and scoring them to find the best placement:
// Simplified scheduler algorithmtype Scheduler struct { profiles map[string]*Profile schedulingQueue PriorityQueue cache Cache}
// scheduleOne attempts to schedule a single pod from the queue// It runs through filtering, scoring, and binding phasesfunc (s *Scheduler) scheduleOne(ctx context.Context) { // 1. Get next pod from queue pod := s.schedulingQueue.Pop() // 2. Find feasible nodes (filtering) nodes := s.cache.ListNodes() feasibleNodes := s.findFeasibleNodes(pod, nodes) if len(feasibleNodes) == 0 { s.recordFailure(pod, "no feasible nodes") return } // 3. Score feasible nodes (scoring) scores := s.prioritizeNodes(pod, feasibleNodes) // 4. Select best node bestNode := s.selectHost(scores) // 5. Reserve resources (pessimistic) s.cache.Reserve(pod, bestNode) // 6. Bind pod to node (async) go s.bind(pod, bestNode)}
func (s *Scheduler) findFeasibleNodes(pod *v1.Pod, nodes []*v1.Node) []*v1.Node { feasible := make([]*v1.Node, 0) // Run filter plugins in parallel checkNode := func(i int) { node := nodes[i] fits := true // Check all filter plugins for _, plugin := range s.filterPlugins { if !plugin.Filter(pod, node) { fits = false break } } if fits { feasible = append(feasible, node) } } parallelize(checkNode, len(nodes)) return feasible}
// Actual filter pluginsvar filterPlugins = []FilterPlugin{ // Resource fit &NodeResourcesFit{}, // CPU, memory, ephemeral-storage &NodePorts{}, // Required host ports available // Volume filters &VolumeBinding{}, // PVC can bind/provision &VolumeRestrictions{}, // Node supports volume types &VolumeZone{}, // Zone constraints // Node selectors &NodeAffinity{}, // Node selector & affinity &NodeTaints{}, // Toleration matching // Pod topology &PodTopologySpread{}, // Even distribution &InterPodAffinity{}, // Pod affinity/anti-affinity}
// Scoring pluginsvar scorePlugins = []ScorePlugin{ &NodeResourcesBalanced{}, // Balance resource usage &NodeResourcesLeastAllocated{}, // Prefer less utilized &NodeAffinity{}, // Prefer affinity matches &PodTopologySpread{}, // Improve spreading &TaintToleration{}, // Prefer untainted &NodeResourcesMostAllocated{}, // Bin packing &RequestedToCapacityRatio{}, // Custom utilization &ImageLocality{}, // Image already cached}Scheduling Framework
The scheduling framework allows extending the scheduler without modifying its core code. Custom plugins can add new filtering criteria (like GPU availability) or scoring functions (like network locality). This extensibility is crucial for specialized workloads like ML training or real-time applications.
Here's how to implement a custom scheduler plugin that considers GPU resources:
// Plugin interface for extending schedulertype Plugin interface { Name() string}
type FilterPlugin interface { Plugin Filter(pod *v1.Pod, node *v1.Node) *Status}
type ScorePlugin interface { Plugin Score(pod *v1.Pod, node *v1.Node) (int64, *Status) NormalizeScore(pod *v1.Pod, scores NodeScoreList) *Status}
// Example: Custom GPU-aware scheduler plugintype GPUScheduler struct{}
func (g *GPUScheduler) Filter(pod *v1.Pod, node *v1.Node) *Status { requestedGPUs := g.getRequestedGPUs(pod) if requestedGPUs == 0 { return NewStatus(Success) } availableGPUs := g.getAvailableGPUs(node) if availableGPUs < requestedGPUs { return NewStatus(Unschedulable, fmt.Sprintf("insufficient GPUs: requested=%d, available=%d", requestedGPUs, availableGPUs)) } // Check GPU type compatibility requestedType := pod.Annotations["gpu.type"] if requestedType != "" { nodeGPUType := node.Labels["gpu.type"] if nodeGPUType != requestedType { return NewStatus(Unschedulable, "GPU type mismatch") } } return NewStatus(Success)}
func (g *GPUScheduler) Score(pod *v1.Pod, node *v1.Node) (int64, *Status) { requestedGPUs := g.getRequestedGPUs(pod) if requestedGPUs == 0 { return 0, NewStatus(Success) } // Prefer nodes with exact GPU count (reduce fragmentation) availableGPUs := g.getAvailableGPUs(node) score := int64(100) if availableGPUs == requestedGPUs { score = 100 // Perfect fit } else if availableGPUs > requestedGPUs { // Penalize fragmentation fragmentation := float64(requestedGPUs) / float64(availableGPUs) score = int64(fragmentation * 80) } return score, NewStatus(Success)}Data Plane Architecture
Node Components Architecture
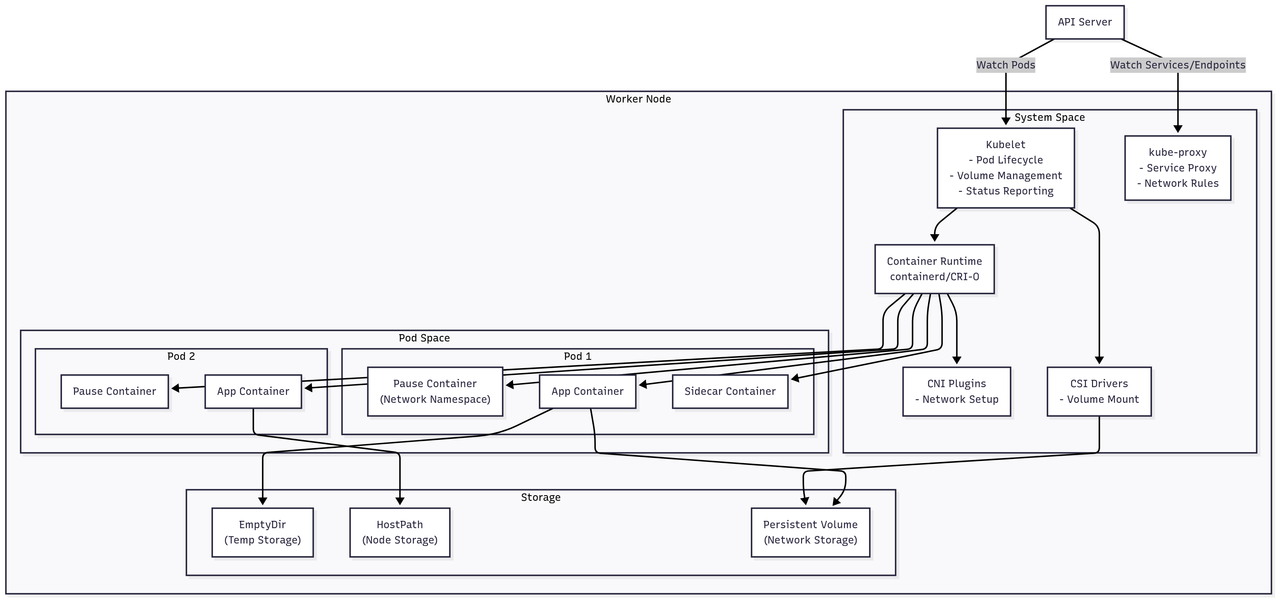
Each Kubernetes node runs several critical components that manage containers and provide the runtime environment:
- Kubelet: The primary node agent that ensures containers are running in pods
- kube-proxy: Maintains network rules for service connectivity
- Container Runtime: The actual engine (containerd/CRI-O) that runs containers
- CNI Plugins: Configure pod networking according to the cluster network model
- CSI Drivers: Handle volume mounting and storage operations
The architecture shows how pods share network namespaces through pause containers, while maintaining isolation between different pods. Storage can be ephemeral (EmptyDir), node-local (HostPath), or persistent (network-attached volumes).
Kubelet: The Node Agent
The kubelet is the primary node agent running on every worker node, responsible for ensuring containers are running in pods. It continuously syncs the desired pod state from the API server with the actual container state on the node. The kubelet manages the entire pod lifecycle - from creating the network namespace to mounting volumes and starting containers.
The sync loop shows how kubelet orchestrates multiple subsystems to bring a pod to life:
// Kubelet main looptype Kubelet struct { podManager PodManager containerRuntime ContainerRuntime volumeManager VolumeManager imageManager ImageManager statusManager StatusManager probeManager ProbeManager}
// syncPod ensures a pod's actual state matches its desired state// It handles the full lifecycle: network setup, volume mounting, and container creationfunc (k *Kubelet) syncPod(pod *v1.Pod, podStatus *PodStatus) error { // 1. Create pod sandbox (network namespace) if !k.podSandboxExists(pod) { sandboxConfig := k.generatePodSandboxConfig(pod) sandboxID, err := k.containerRuntime.RunPodSandbox(sandboxConfig) if err != nil { return err } } // 2. Mount volumes if err := k.volumeManager.WaitForAttachAndMount(pod); err != nil { return err } // 3. Pull images for _, container := range pod.Spec.Containers { if err := k.imageManager.EnsureImageExists(container.Image); err != nil { return err } } // 4. Create init containers (sequential) for _, initContainer := range pod.Spec.InitContainers { if err := k.runInitContainer(pod, initContainer); err != nil { return err } } // 5. Create containers (parallel) for _, container := range pod.Spec.Containers { if !k.containerExists(pod, container) { if err := k.runContainer(pod, container, sandboxID); err != nil { return err } } } // 6. Start probes k.probeManager.AddPod(pod) return nil}
// runContainer creates and starts a container within a pod sandbox// It executes lifecycle hooks and ensures the container is properly configuredfunc (k *Kubelet) runContainer(pod *v1.Pod, container v1.Container, sandboxID string) error { // PreStart hook if container.Lifecycle != nil && container.Lifecycle.PostStart != nil { if err := k.runner.Run(container.Lifecycle.PostStart); err != nil { return err } } // Create container containerConfig := k.generateContainerConfig(container, pod, sandboxID) containerID, err := k.containerRuntime.CreateContainer(sandboxID, containerConfig) if err != nil { return err } // Start container if err := k.containerRuntime.StartContainer(containerID); err != nil { return err } // PostStart hook if container.Lifecycle != nil && container.Lifecycle.PostStart != nil { // Run asynchronously go k.runner.Run(container.Lifecycle.PostStart) } return nil}Container Runtime Interface (CRI)
CRI standardizes how Kubernetes talks to container runtimes, enabling support for Docker, containerd, CRI-O, and others without changing kubelet code. The interface defines two services: RuntimeService for container/pod operations and ImageService for image management. All communication happens over gRPC for performance and language independence.
The protocol definition shows the operations kubelet can request from the runtime:
// CRI Protocol (gRPC)service RuntimeService { // Sandbox operations rpc RunPodSandbox(RunPodSandboxRequest) returns (RunPodSandboxResponse) {} rpc StopPodSandbox(StopPodSandboxRequest) returns (StopPodSandboxResponse) {} rpc RemovePodSandbox(RemovePodSandboxRequest) returns (RemovePodSandboxResponse) {} // Container operations rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {} rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {} rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {} rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse) {} // Exec/Attach rpc Exec(ExecRequest) returns (ExecResponse) {} rpc Attach(AttachRequest) returns (AttachResponse) {}}
service ImageService { rpc ListImages(ListImagesRequest) returns (ListImagesResponse) {} rpc ImageStatus(ImageStatusRequest) returns (ImageStatusResponse) {} rpc PullImage(PullImageRequest) returns (PullImageResponse) {} rpc RemoveImage(RemoveImageRequest) returns (RemoveImageResponse) {}}containerd Integration
containerd is now the default container runtime for Kubernetes, providing a minimal, stable interface for container operations. When kubelet needs to create a pod, it first creates a sandbox (pause container) that holds the network namespace, then adds application containers to that sandbox. This architecture enables pod-level resource sharing while maintaining container isolation.
Here's how kubelet creates a pod sandbox using containerd's API:
// How kubelet talks to containerdtype ContainerdRuntime struct { client containerd.Client}
// RunPodSandbox creates the pod's network namespace and pause container// This provides the shared network and IPC namespaces for all pod containersfunc (c *ContainerdRuntime) RunPodSandbox(config *runtimeapi.PodSandboxConfig) (string, error) { // 1. Create network namespace namespace := fmt.Sprintf("k8s.io.%s", config.Metadata.Uid) // 2. Setup network networkConfig := &cni.NetworkConfig{ Name: "k8s-pod-network", Namespace: config.Metadata.Namespace, PodName: config.Metadata.Name, } ip, err := c.cniPlugin.Setup(namespace, networkConfig) if err != nil { return "", err } // 3. Create sandbox container (pause container) container, err := c.client.NewContainer( context.Background(), config.Metadata.Name, containerd.WithImage("k8s.gcr.io/pause:3.7"), containerd.WithNamespace(namespace), containerd.WithRuntime("io.containerd.runc.v2", nil), containerd.WithSpec(&specs.Spec{ Hostname: config.Hostname, Networks: []specs.Network{{ Type: "loopback", }}, }), ) // 4. Start sandbox task, err := container.NewTask(context.Background(), cio.NewCreator()) if err != nil { return "", err } if err := task.Start(context.Background()); err != nil { return "", err } return container.ID(), nil}Networking Architecture
Kubernetes Networking Model
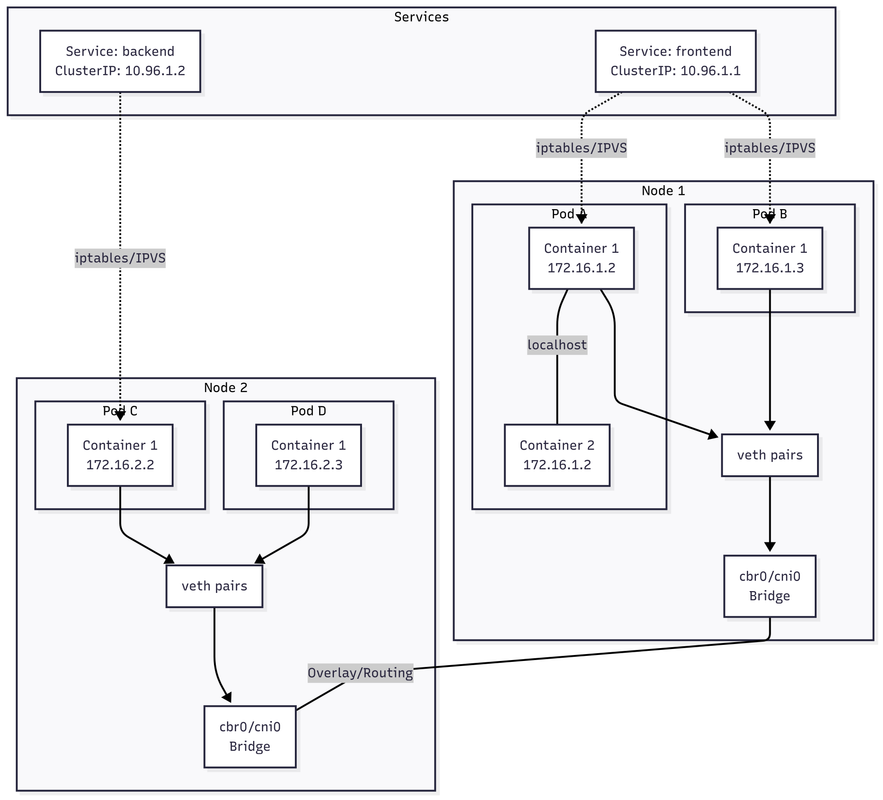
The diagram illustrates Kubernetes' flat network model where:
- All containers within a pod share the same network namespace (same IP)
- Pods can communicate directly without NAT
- Services provide stable virtual IPs that load balance to pod endpoints
- Network plugins (CNI) implement the actual connectivity using overlays, routing, or SDN
Cluster Networking Model
Kubernetes networking has four requirements:
- Containers in a pod can communicate via localhost
- All pods can communicate with all pods without NAT
- All nodes can communicate with all pods without NAT
- The IP a pod sees itself as is the same IP others see
These requirements enable a flat network model where every pod gets a unique IP address, simplifying application development. No port mapping or NAT translation is needed. This model is implemented by CNI plugins that handle the actual packet routing.
Here's how a pod's network namespace is created and configured:
// Network namespace sharing in a podtype PodNetwork struct { namespace string interfaces []Interface routes []Route iptables IPTables}
func (pn *PodNetwork) Setup(pod *v1.Pod) error { // 1. Create network namespace ns, err := netns.New() if err != nil { return err } // 2. Create veth pair vethHost := fmt.Sprintf("veth%s", pod.UID[:8]) vethPod := "eth0" if err := netlink.LinkAdd(&netlink.Veth{ LinkAttrs: netlink.LinkAttrs{Name: vethHost}, PeerName: vethPod, }); err != nil { return err } // 3. Move pod end to namespace veth, _ := netlink.LinkByName(vethPod) netlink.LinkSetNsFd(veth, int(ns)) // 4. Configure pod interface netns.Do(ns, func() error { // Bring up loopback lo, _ := netlink.LinkByName("lo") netlink.LinkSetUp(lo) // Configure eth0 eth0, _ := netlink.LinkByName("eth0") netlink.AddrAdd(eth0, &netlink.Addr{ IPNet: &net.IPNet{ IP: pod.Status.PodIP, Mask: net.CIDRMask(24, 32), }, }) netlink.LinkSetUp(eth0) // Add default route netlink.RouteAdd(&netlink.Route{ LinkIndex: eth0.Attrs().Index, Dst: nil, // default Gw: net.ParseIP("10.244.0.1"), }) return nil }) // 5. Connect host end to bridge bridge, _ := netlink.LinkByName("cni0") netlink.LinkSetMaster(vethHost, bridge) netlink.LinkSetUp(vethHost) return nil}CNI (Container Network Interface)
CNI standardizes how network plugins provide connectivity to containers. When a pod starts, kubelet calls the CNI plugin to set up networking - creating veth pairs, configuring bridges, and setting up routing. Popular CNI plugins include Calico (BGP-based), Cilium (eBPF-based), and Flannel (overlay-based). Each implements the same interface but with different underlying technologies.
This example shows how a bridge CNI plugin sets up pod networking:
// CNI plugin interfacetype CNI interface { AddNetwork(ctx context.Context, net *NetworkConfig, rt *RuntimeConf) (*Result, error) DelNetwork(ctx context.Context, net *NetworkConfig, rt *RuntimeConf) error}
// Example: Bridge CNI plugintype BridgePlugin struct { BridgeName string Subnet *net.IPNet Gateway net.IP}
// AddNetwork sets up networking for a new pod using the bridge CNI plugin// It creates veth pairs, assigns IPs, and configures routingfunc (b *BridgePlugin) AddNetwork(ctx context.Context, config *NetworkConfig, rt *RuntimeConf) (*Result, error) { // 1. Ensure bridge exists bridge := b.ensureBridge() // 2. Allocate IP from IPAM ip, err := b.ipam.Allocate(rt.ContainerID) if err != nil { return nil, err } // 3. Create veth pair hostVeth, containerVeth := b.createVethPair(rt.ContainerID) // 4. Move container end to netns b.moveToNetns(containerVeth, rt.NetNS) // 5. Configure container interface b.configureInterface(containerVeth, ip, rt.NetNS) // 6. Add host veth to bridge b.addToBridge(hostVeth, bridge) // 7. Setup iptables rules b.setupIPTables(ip) return &Result{ IPs: []*IPConfig{{ Address: *ip, Gateway: b.Gateway, }}, }, nil}Service Networking
Services provide stable network endpoints for pods, solving the problem of pods having ephemeral IPs. When you create a Service, Kubernetes allocates a cluster IP and programs every node to route traffic for that IP to the service's pods. This happens through either iptables rules or IPVS load balancing, depending on the proxy mode.
The service controller shows how cluster IPs are allocated and load balancing is configured:
// How Services worktype ServiceController struct { client kubernetes.Interface ipvs IPVS iptables IPTables endpointMap map[string][]Endpoint}
func (s *ServiceController) syncService(service *v1.Service) error { // 1. Allocate ClusterIP if needed if service.Spec.ClusterIP == "" && service.Spec.Type != v1.ServiceTypeExternalName { ip, err := s.allocateIP() if err != nil { return err } service.Spec.ClusterIP = ip.String() } // 2. Get endpoints endpoints := s.endpointMap[service.Name] // 3. Program load balancer (IPVS mode) virtualServer := &ipvs.VirtualServer{ Address: net.ParseIP(service.Spec.ClusterIP), Port: uint16(service.Spec.Ports[0].Port), Protocol: "tcp", Scheduler: "rr", // round-robin } s.ipvs.AddVirtualServer(virtualServer) // 4. Add real servers (endpoints) for _, endpoint := range endpoints { realServer := &ipvs.RealServer{ Address: endpoint.IP, Port: endpoint.Port, Weight: 1, } s.ipvs.AddRealServer(virtualServer, realServer) } // 5. Setup iptables for NodePort (if applicable) if service.Spec.Type == v1.ServiceTypeNodePort { for _, port := range service.Spec.Ports { s.setupNodePort(port.NodePort, service.Spec.ClusterIP, port.Port) } } return nil}
// Iptables rules for services// This function creates the complex iptables chains that implement service load balancing// KUBE-SERVICES is the main chain, with per-service and per-endpoint chains for routingfunc (s *ServiceController) setupIPTablesRules() { // KUBE-SERVICES chain s.iptables.NewChain("nat", "KUBE-SERVICES") s.iptables.AppendRule("nat", "PREROUTING", "-j", "KUBE-SERVICES") s.iptables.AppendRule("nat", "OUTPUT", "-j", "KUBE-SERVICES") // Per-service rules for _, svc := range s.services { svcChain := fmt.Sprintf("KUBE-SVC-%s", hash(svc.Name)) s.iptables.NewChain("nat", svcChain) // Jump to service chain for ClusterIP s.iptables.AppendRule("nat", "KUBE-SERVICES", "-d", svc.ClusterIP, "-p", "tcp", "--dport", fmt.Sprint(svc.Port), "-j", svcChain) // Load balance to endpoints endpoints := s.endpointMap[svc.Name] for i, ep := range endpoints { epChain := fmt.Sprintf("KUBE-SEP-%s-%d", hash(svc.Name), i) s.iptables.NewChain("nat", epChain) // Probability for load balancing prob := 1.0 / float64(len(endpoints)-i) s.iptables.AppendRule("nat", svcChain, "-m", "statistic", "--mode", "random", "--probability", fmt.Sprint(prob), "-j", epChain) // DNAT to endpoint s.iptables.AppendRule("nat", epChain, "-p", "tcp", "-j", "DNAT", "--to-destination", fmt.Sprintf("%s:%d", ep.IP, ep.Port)) } }}Ingress and Load Balancing
Ingress controllers expose HTTP/HTTPS services to the external world, providing features like SSL termination, name-based virtual hosting, and path-based routing. Most ingress controllers (nginx, HAProxy, Traefik) work by watching Ingress resources and dynamically reconfiguring their proxy based on the rules. They integrate with cloud load balancers for production deployments.
This implementation shows how an nginx-based ingress controller generates configuration from Ingress resources:
// Ingress controller implementationtype IngressController struct { client kubernetes.Interface nginxManager *NginxManager}
func (ic *IngressController) syncIngress(ingress *networkingv1.Ingress) error { // Generate nginx configuration config := ic.generateNginxConfig(ingress) // Update nginx return ic.nginxManager.UpdateConfig(config)}
// generateNginxConfig creates nginx configuration from Ingress rules// It sets up server blocks, SSL certificates, and upstream backendsfunc (ic *IngressController) generateNginxConfig(ingress *networkingv1.Ingress) string { var config strings.Builder for _, rule := range ingress.Spec.Rules { config.WriteString(fmt.Sprintf("server {\n")) config.WriteString(fmt.Sprintf(" server_name %s;\n", rule.Host)) if ingress.Spec.TLS != nil { config.WriteString(fmt.Sprintf(" listen 443 ssl;\n")) config.WriteString(fmt.Sprintf(" ssl_certificate /etc/nginx/ssl/%s.crt;\n", rule.Host)) config.WriteString(fmt.Sprintf(" ssl_certificate_key /etc/nginx/ssl/%s.key;\n", rule.Host)) } else { config.WriteString(fmt.Sprintf(" listen 80;\n")) } for _, path := range rule.HTTP.Paths { config.WriteString(fmt.Sprintf("\n location %s {\n", path.Path)) // Get service endpoints service, _ := ic.client.CoreV1().Services(ingress.Namespace).Get( context.TODO(), path.Backend.Service.Name, metav1.GetOptions{}) endpoints, _ := ic.client.CoreV1().Endpoints(ingress.Namespace).Get( context.TODO(), path.Backend.Service.Name, metav1.GetOptions{}) // Configure upstream upstreamName := fmt.Sprintf("%s_%s_%d", ingress.Namespace, path.Backend.Service.Name, path.Backend.Service.Port.Number) config.WriteString(fmt.Sprintf(" proxy_pass http://%s;\n", upstreamName)) config.WriteString(" proxy_set_header Host $host;\n") config.WriteString(" proxy_set_header X-Real-IP $remote_addr;\n") config.WriteString(" }\n") } config.WriteString("}\n\n") } // Generate upstreams for _, rule := range ingress.Spec.Rules { for _, path := range rule.HTTP.Paths { endpoints, _ := ic.client.CoreV1().Endpoints(ingress.Namespace).Get( context.TODO(), path.Backend.Service.Name, metav1.GetOptions{}) upstreamName := fmt.Sprintf("%s_%s_%d", ingress.Namespace, path.Backend.Service.Name, path.Backend.Service.Port.Number) config.WriteString(fmt.Sprintf("upstream %s {\n", upstreamName)) for _, subset := range endpoints.Subsets { for _, addr := range subset.Addresses { config.WriteString(fmt.Sprintf(" server %s:%d;\n", addr.IP, path.Backend.Service.Port.Number)) } } config.WriteString("}\n\n") } } return config.String()}Storage Architecture
Storage Lifecycle
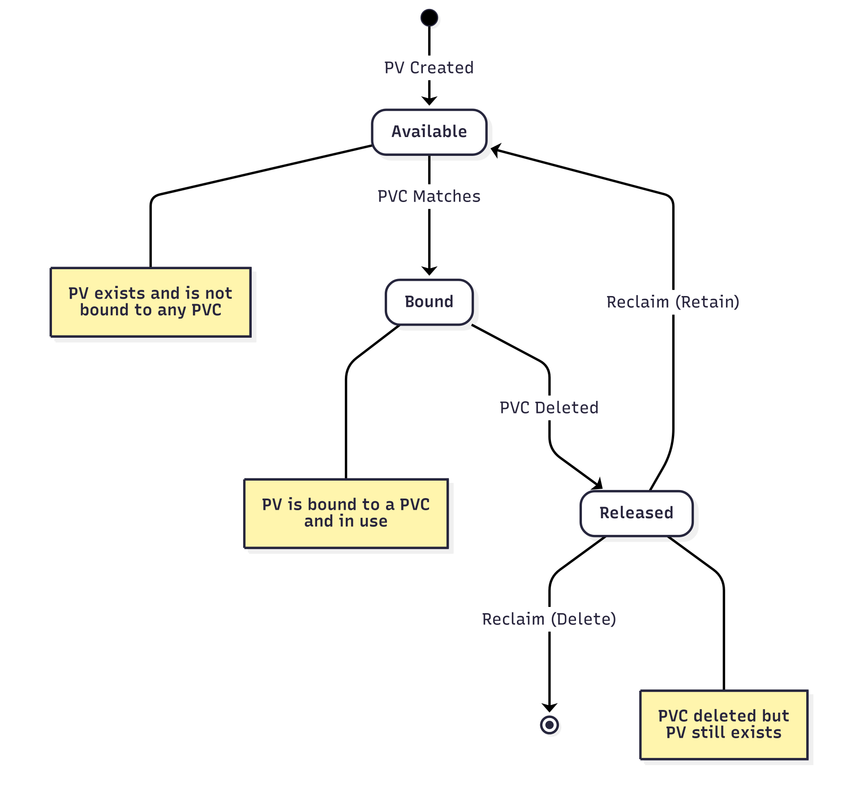
Persistent Volumes (PVs) follow a defined lifecycle:
- Available: PV exists and is ready to be bound to a claim
- Bound: PV is exclusively attached to a PVC and in use
- Released: PVC has been deleted but PV still contains data
- Reclaim Policy: Determines what happens after release (Retain, Delete, or Recycle)
Dynamic Provisioning Flow
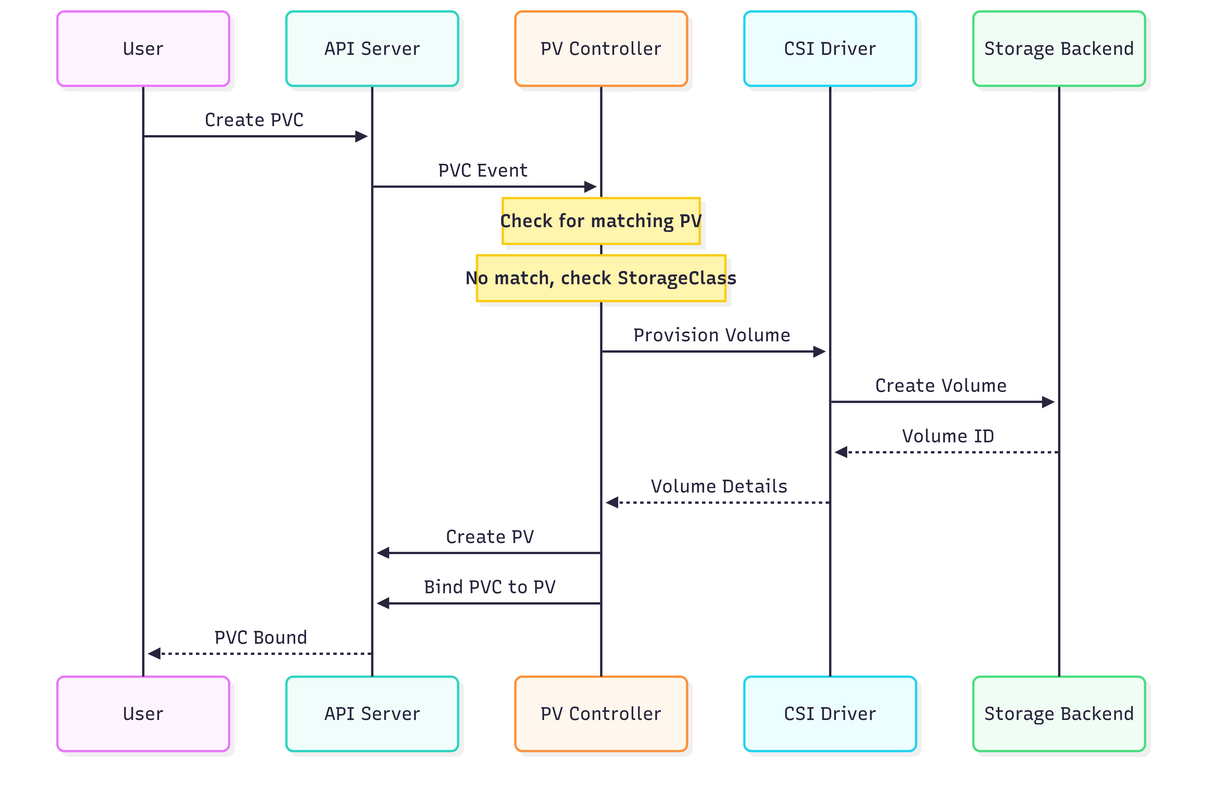
Dynamic provisioning automates storage creation:
- User creates a PVC requesting storage
- PV Controller checks for matching PVs
- If no match, controller invokes the CSI driver
- CSI driver provisions storage on the backend
- Controller creates PV and binds it to PVC
- When pod uses PVC, kubelet attaches and mounts the volume
This flow eliminates manual PV pre-provisioning for administrators.
Persistent Volume Subsystem
The PV/PVC controller manages the binding between persistent volumes and claims, implementing the storage orchestration logic. It matches PVCs to available PVs based on storage class, capacity, access modes, and selectors. When no matching PV exists, it triggers dynamic provisioning through the storage class provisioner. The controller also handles cleanup when PVCs are deleted, implementing the reclaim policy.
This controller code shows the matching algorithm and binding process:
// PV/PVC Controllertype PVController struct { client kubernetes.Interface pvLister PVLister pvcLister PVCLister provisioner Provisioner}
func (c *PVController) syncPVC(pvc *v1.PersistentVolumeClaim) error { // 1. Check if already bound if pvc.Spec.VolumeName != "" { return c.ensurePVBound(pvc) } // 2. Find matching PV pv := c.findMatchingPV(pvc) if pv == nil { // 3. Dynamic provisioning if c.shouldProvision(pvc) { return c.provisionVolume(pvc) } return fmt.Errorf("no matching PV found") } // 4. Bind PVC to PV return c.bind(pvc, pv)}
func (c *PVController) findMatchingPV(pvc *v1.PersistentVolumeClaim) *v1.PersistentVolume { pvs, _ := c.pvLister.List(labels.Everything()) for _, pv := range pvs { // Check if available if pv.Status.Phase != v1.VolumeAvailable { continue } // Check access modes if !c.accessModesMatch(pv.Spec.AccessModes, pvc.Spec.AccessModes) { continue } // Check capacity pvQty := pv.Spec.Capacity[v1.ResourceStorage] pvcQty := pvc.Spec.Resources.Requests[v1.ResourceStorage] if pvQty.Cmp(pvcQty) < 0 { continue } // Check selector if pvc.Spec.Selector != nil { if !pvc.Spec.Selector.Matches(labels.Set(pv.Labels)) { continue } } // Check storage class if pvc.Spec.StorageClassName != nil { if pv.Spec.StorageClassName != *pvc.Spec.StorageClassName { continue } } return pv } return nil}
// provisionVolume triggers dynamic volume creation when no matching PV exists// It uses the StorageClass to determine which provisioner to use and what parameters to passfunc (c *PVController) provisionVolume(pvc *v1.PersistentVolumeClaim) error { // Get storage class storageClass, err := c.client.StorageV1().StorageClasses().Get( context.TODO(), *pvc.Spec.StorageClassName, metav1.GetOptions{}) if err != nil { return err } // Get provisioner provisioner := c.getProvisioner(storageClass.Provisioner) // Provision volume pv, err := provisioner.Provision(ProvisionOptions{ PVC: pvc, StorageClass: storageClass, Node: c.getSelectedNode(pvc), }) if err != nil { return err } // Create PV pv, err = c.client.CoreV1().PersistentVolumes().Create( context.TODO(), pv, metav1.CreateOptions{}) if err != nil { return err } // Bind PVC to new PV return c.bind(pvc, pv)}CSI (Container Storage Interface)
CSI provides a standard interface for storage vendors to integrate with Kubernetes without modifying core code. A CSI driver implements three services: Identity (driver info), Controller (volume provisioning/attachment), and Node (volume mounting). This separation allows the controller plugin to run centrally while node plugins run on every node. CSI has replaced in-tree volume plugins, making Kubernetes more maintainable and extensible.
This example shows how a CSI driver provisions and mounts volumes:
// CSI Driver implementationtype CSIDriver struct { name string endpoint string conn *grpc.ClientConn}
func (d *CSIDriver) CreateVolume(req *csi.CreateVolumeRequest) (*csi.CreateVolumeResponse, error) { // 1. Validate request if req.Name == "" { return nil, status.Error(codes.InvalidArgument, "volume name required") } // 2. Check if volume exists existingVolume := d.getVolume(req.Name) if existingVolume != nil { return &csi.CreateVolumeResponse{Volume: existingVolume}, nil } // 3. Create volume on storage backend volumeID := d.createBackendVolume(req) // 4. Return CSI volume return &csi.CreateVolumeResponse{ Volume: &csi.Volume{ VolumeId: volumeID, CapacityBytes: req.CapacityRange.RequiredBytes, VolumeContext: req.Parameters, AccessibleTopology: []*csi.Topology{{ Segments: map[string]string{ "topology.kubernetes.io/zone": d.zone, }, }}, }, }, nil}
// NodeStageVolume is called by kubelet to attach and format a volume on the node// This is a two-phase mount: first stage (attach/format), then publish (mount to pod)func (d *CSIDriver) NodeStageVolume(req *csi.NodeStageVolumeRequest) (*csi.NodeStageVolumeResponse, error) { // 1. Attach volume to node (if block storage) devicePath, err := d.attachVolume(req.VolumeId) if err != nil { return nil, err } // 2. Format if needed if needsFormat(devicePath) { fsType := req.VolumeCapability.GetMount().FsType if fsType == "" { fsType = "ext4" } if err := formatDevice(devicePath, fsType); err != nil { return nil, err } } // 3. Mount to staging path stagingPath := req.StagingTargetPath if err := mount(devicePath, stagingPath, fsType); err != nil { return nil, err } return &csi.NodeStageVolumeResponse{}, nil}
// NodePublishVolume mounts the volume from staging path to the pod's volume path// This is called after NodeStageVolume and makes the volume available to the podfunc (d *CSIDriver) NodePublishVolume(req *csi.NodePublishVolumeRequest) (*csi.NodePublishVolumeResponse, error) { // Bind mount from staging to target source := req.StagingTargetPath target := req.TargetPath if err := bindMount(source, target, req.Readonly); err != nil { return nil, err } return &csi.NodePublishVolumeResponse{}, nil}Security Architecture
Security Layers
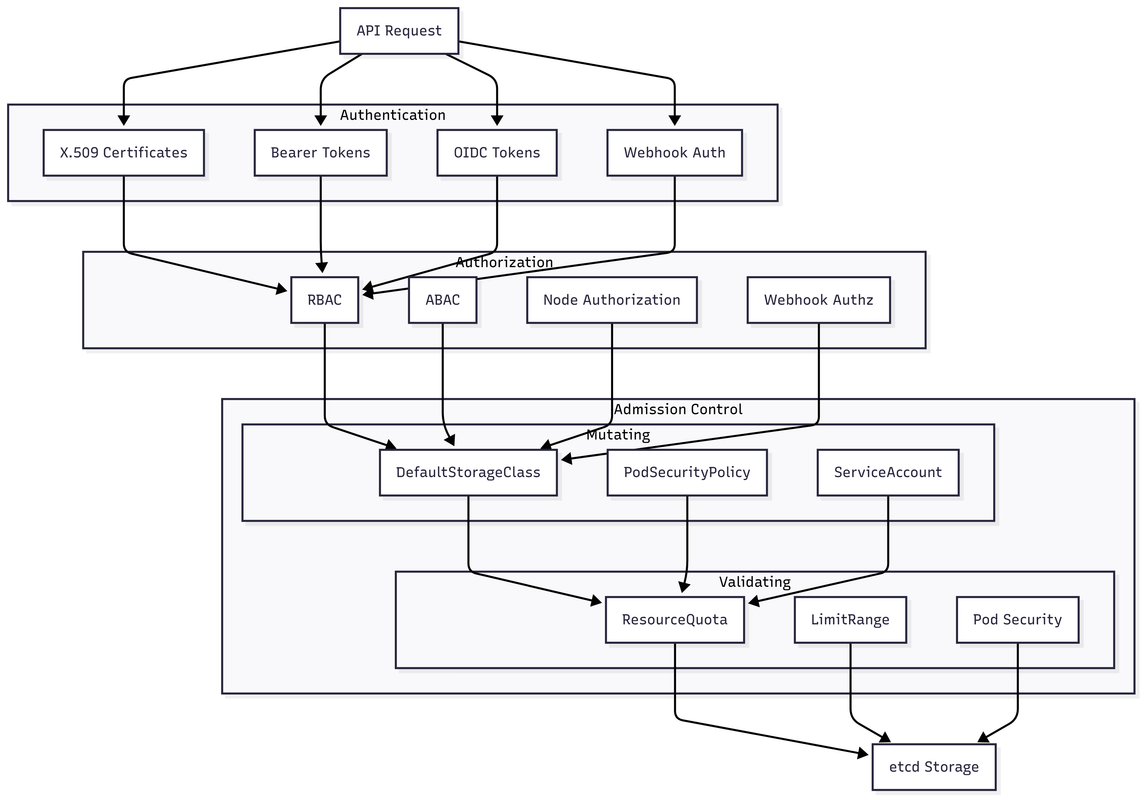
Kubernetes implements defense in depth with multiple security layers:
- Authentication: Verifies identity (X.509 certs, tokens, OIDC, webhooks)
- Authorization: Determines permissions (RBAC, ABAC, Node, Webhook)
- Admission Control: Mutates and validates requests before persistence
- Storage: Final persistence to etcd after all checks pass
Each layer can reject requests independently, ensuring comprehensive security.
Authentication
Kubernetes supports multiple authentication methods simultaneously, trying each until one succeeds. X.509 certificates are commonly used for service accounts and admin access, while bearer tokens and OIDC are popular for user authentication. The authentication layer only establishes identity - it doesn't determine what actions are allowed.
These authentication plugins show how different methods validate identity:
// Authentication pluginstype Authenticator interface { AuthenticateRequest(req *http.Request) (*user.DefaultInfo, bool, error)}
// X.509 Client Certificate Authenticationtype X509Authenticator struct { caBundle *x509.CertPool}
func (a *X509Authenticator) AuthenticateRequest(req *http.Request) (*user.DefaultInfo, bool, error) { if req.TLS == nil || len(req.TLS.PeerCertificates) == 0 { return nil, false, nil } cert := req.TLS.PeerCertificates[0] // Verify certificate opts := x509.VerifyOptions{ Roots: a.caBundle, KeyUsages: []x509.ExtKeyUsage{x509.ExtKeyUsageClientAuth}, } if _, err := cert.Verify(opts); err != nil { return nil, false, err } // Extract user info from certificate return &user.DefaultInfo{ Name: cert.Subject.CommonName, Groups: cert.Subject.Organization, UID: string(cert.SerialNumber.Bytes()), }, true, nil}
// Bearer Token Authentication validates tokens by calling the TokenReview API// This allows external systems to validate tokens without sharing secretstype BearerTokenAuthenticator struct { tokenReview TokenReviewInterface}
func (b *BearerTokenAuthenticator) AuthenticateRequest(req *http.Request) (*user.DefaultInfo, bool, error) { token := extractBearer(req.Header.Get("Authorization")) if token == "" { return nil, false, nil } // Call TokenReview API review := &authv1.TokenReview{ Spec: authv1.TokenReviewSpec{ Token: token, }, } result, err := b.tokenReview.Create(context.TODO(), review, metav1.CreateOptions{}) if err != nil { return nil, false, err } if !result.Status.Authenticated { return nil, false, nil } return &user.DefaultInfo{ Name: result.Status.User.Username, UID: result.Status.User.UID, Groups: result.Status.User.Groups, Extra: result.Status.User.Extra, }, true, nil}Authorization (RBAC)
Role-Based Access Control (RBAC) is the primary authorization mechanism in Kubernetes, evaluating requests against roles and bindings:
// RBAC Authorizertype RBACAuthorizer struct { roleBindingLister RoleBindingLister roleLister RoleLister}
// Authorize evaluates whether a user can perform an action by checking their roles and bindings// It iterates through all applicable roles until finding a matching rule or denying accessfunc (r *RBACAuthorizer) Authorize(attrs auth.Attributes) (auth.Decision, string, error) { // 1. Get user's roles roles := r.getRolesForUser(attrs.GetUser()) // 2. Check each role for _, role := range roles { for _, rule := range role.Rules { if r.ruleMatches(rule, attrs) { return auth.DecisionAllow, fmt.Sprintf("RBAC: allowed by %s", role.Name), nil } } } return auth.DecisionDeny, "RBAC: no rules matched", nil}
// ruleMatches determines if a PolicyRule grants permission for the requested action// It checks verbs, API groups, resources, and optionally resource namesfunc (r *RBACAuthorizer) ruleMatches(rule rbacv1.PolicyRule, attrs auth.Attributes) bool { // Check verb verbMatches := false for _, verb := range rule.Verbs { if verb == "*" || verb == attrs.GetVerb() { verbMatches = true break } } if !verbMatches { return false } // Check API group groupMatches := false for _, group := range rule.APIGroups { if group == "*" || group == attrs.GetAPIGroup() { groupMatches = true break } } if !groupMatches { return false } // Check resource resourceMatches := false for _, resource := range rule.Resources { if resource == "*" || resource == attrs.GetResource() { resourceMatches = true break } } if !resourceMatches { return false } // Check resource name if specified if len(rule.ResourceNames) > 0 { nameMatches := false for _, name := range rule.ResourceNames { if name == attrs.GetName() { nameMatches = true break } } if !nameMatches { return false } } return true}Admission Control
Admission controllers intercept requests after authentication and authorization but before persistence, allowing mutation and validation:
// Admission webhooktype AdmissionWebhook struct { client WebhookClient}
// Admit calls an external webhook to validate or mutate the admission request// Webhooks can reject requests, modify objects, or simply audit actionsfunc (w *AdmissionWebhook) Admit(attrs admission.Attributes) error { // Build admission review request review := &admissionv1.AdmissionReview{ Request: &admissionv1.AdmissionRequest{ UID: attrs.GetUID(), Kind: attrs.GetKind(), Resource: attrs.GetResource(), SubResource: attrs.GetSubResource(), Name: attrs.GetName(), Namespace: attrs.GetNamespace(), Operation: attrs.GetOperation(), UserInfo: attrs.GetUserInfo(), Object: attrs.GetObject(), OldObject: attrs.GetOldObject(), Options: attrs.GetOptions(), }, } // Call webhook response, err := w.client.Call(review) if err != nil { return err } if !response.Response.Allowed { return fmt.Errorf("admission denied: %s", response.Response.Result.Message) } // Apply mutations if any if len(response.Response.Patch) > 0 { if err := applyPatch(attrs.GetObject(), response.Response.Patch); err != nil { return err } } return nil}
// Pod Security Policy Admission enforces security constraints on pods// It validates pods against policies and mutates them to comply with requirements// Note: PSP is deprecated in favor of Pod Security Standardstype PodSecurityPolicyAdmission struct { policies []PodSecurityPolicy}
func (p *PodSecurityPolicyAdmission) Admit(attrs admission.Attributes) error { if attrs.GetKind().GroupKind() != v1.SchemeGroupVersion.WithKind("Pod").GroupKind() { return nil } pod := attrs.GetObject().(*v1.Pod) // Find applicable PSP psp := p.findApplicablePSP(pod, attrs.GetUserInfo()) if psp == nil { return fmt.Errorf("no pod security policy found") } // Validate pod against PSP if err := p.validatePod(pod, psp); err != nil { return err } // Mutate pod to comply with PSP p.mutatePod(pod, psp) return nil}
// validatePod ensures a pod complies with security policy requirements// It checks privileged mode, capabilities, volumes, and other security settingsfunc (p *PodSecurityPolicyAdmission) validatePod(pod *v1.Pod, psp *PodSecurityPolicy) error { // Check privileged for _, container := range pod.Spec.Containers { if container.SecurityContext != nil && container.SecurityContext.Privileged != nil && *container.SecurityContext.Privileged && !psp.Spec.Privileged { return fmt.Errorf("privileged containers not allowed") } } // Check capabilities for _, container := range pod.Spec.Containers { if container.SecurityContext != nil && container.SecurityContext.Capabilities != nil { for _, cap := range container.SecurityContext.Capabilities.Add { if !p.capabilityAllowed(cap, psp.Spec.AllowedCapabilities) { return fmt.Errorf("capability %s not allowed", cap) } } } } // Check volumes for _, volume := range pod.Spec.Volumes { if !p.volumeAllowed(volume, psp.Spec.Volumes) { return fmt.Errorf("volume type not allowed") } } return nil}High Availability and Scaling
Control Plane HA
High availability control plane configuration ensures cluster resilience through redundancy and leader election:
# HA Control Plane SetupapiVersion: kubeadm.k8s.io/v1beta3kind: ClusterConfigurationkubernetesVersion: v1.26.0controlPlaneEndpoint: "api.k8s.example.com:6443" # Load balancer endpoint
# etcd configurationetcd: external: endpoints: - https://etcd-1.example.com:2379 - https://etcd-2.example.com:2379 - https://etcd-3.example.com:2379 caFile: /etc/kubernetes/pki/etcd/ca.crt certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
# API Server configurationapiServer: extraArgs: # Performance max-requests-inflight: "1000" max-mutating-requests-inflight: "500" # Audit audit-log-path: /var/log/kubernetes/audit.log audit-log-maxage: "30" audit-log-maxbackup: "10" audit-log-maxsize: "100" # Encryption encryption-provider-config: /etc/kubernetes/encryption-config.yaml
# Controller Manager configurationcontrollerManager: extraArgs: # Performance concurrent-deployment-syncs: "10" concurrent-replicaset-syncs: "10" concurrent-service-syncs: "5" # HA leader-elect: "true" leader-elect-lease-duration: "15s" leader-elect-renew-deadline: "10s" leader-elect-retry-period: "2s"
# Scheduler configurationscheduler: extraArgs: # HA leader-elect: "true" # Performance scheduling-queue-size: "10000"Large Scale Optimizations
When running Kubernetes at scale (5000+ nodes), specific optimizations are crucial for performance and stability:
// Optimizations for 5000+ node clusterstype LargeScaleOptimizations struct{}
// ConfigureAPIServer returns optimized settings for large clusters// These settings increase limits, enable caching, and tune performance parametersfunc (o *LargeScaleOptimizations) ConfigureAPIServer() map[string]string { return map[string]string{ // Increase limits "--max-requests-inflight": "3000", "--max-mutating-requests-inflight": "1000", // Enable request priorities "--enable-priority-and-fairness": "true", // Optimize watch "--watch-cache-sizes": "deployments#1000,pods#5000", // Request timeout "--request-timeout": "1m", // Profiling "--profiling": "true", // Compression "--disable-admission-plugins": "DefaultStorageClass", }}
func (o *LargeScaleOptimizations) ConfigureKubelet() map[string]string { return map[string]string{ // Status updates "--node-status-update-frequency": "10s", "--node-status-report-frequency": "5m", // Image GC "--image-gc-high-threshold": "85", "--image-gc-low-threshold": "80", "--minimum-image-ttl-duration": "2m", // Eviction "--eviction-hard": "memory.available<100Mi,nodefs.available<10%", "--eviction-soft": "memory.available<300Mi,nodefs.available<15%", "--eviction-soft-grace-period": "memory.available=1m,nodefs.available=1m", // QPS limits "--kube-api-qps": "50", "--kube-api-burst": "100", // Pod limits "--max-pods": "110", // Serialize image pulls "--serialize-image-pulls": "false", }}
func (o *LargeScaleOptimizations) ConfigureControllerManager() map[string]string { return map[string]string{ // Increase concurrency "--concurrent-deployment-syncs": "50", "--concurrent-replicaset-syncs": "50", "--concurrent-statefulset-syncs": "20", "--concurrent-daemonset-syncs": "10", "--concurrent-job-syncs": "20", "--concurrent-endpoint-syncs": "20", "--concurrent-service-syncs": "10", "--concurrent-namespace-syncs": "20", "--concurrent-gc-syncs": "30", // Node lifecycle "--node-monitor-period": "5s", "--node-monitor-grace-period": "40s", "--pod-eviction-timeout": "5m", // QPS "--kube-api-qps": "100", "--kube-api-burst": "200", }}Performance Monitoring and Debugging
Key Metrics
Monitoring these critical metrics helps maintain cluster health and performance:
# Prometheus queries for monitoring Kuberneteskey_metrics: # API Server api_server_latency: query: histogram_quantile(0.99, rate(apiserver_request_duration_seconds_bucket[5m])) description: 99th percentile API request latency api_server_error_rate: query: sum(rate(apiserver_request_total{code=~"5.."}[5m])) / sum(rate(apiserver_request_total[5m])) description: API server error rate # etcd etcd_latency: query: histogram_quantile(0.99, rate(etcd_request_duration_seconds_bucket[5m])) description: etcd request latency etcd_db_size: query: etcd_mvcc_db_total_size_in_bytes description: etcd database size # Scheduler scheduling_latency: query: scheduler_scheduling_duration_seconds{quantile="0.99"} description: Time to schedule pods pending_pods: query: scheduler_pending_pods description: Number of pending pods # Controller Manager controller_queue_depth: query: workqueue_depth description: Controller work queue depth controller_sync_duration: query: histogram_quantile(0.99, rate(controller_sync_duration_seconds_bucket[5m])) description: Controller sync duration # Kubelet pod_startup_latency: query: kubelet_pod_start_duration_seconds{quantile="0.99"} description: Pod startup time container_cpu_usage: query: sum(rate(container_cpu_usage_seconds_total[5m])) by (pod, container) description: Container CPU usage container_memory_usage: query: container_memory_working_set_bytes description: Container memory usageDebugging Tools
This comprehensive debugging script helps diagnose cluster issues by checking all critical components:
#!/bin/bash# debug-cluster.sh
# Check component healthecho "=== Component Health ==="kubectl get componentstatus
# Check node statusecho "=== Node Status ==="kubectl get nodes -o widekubectl top nodes
# Check system podsecho "=== System Pods ==="kubectl get pods -n kube-system -o wide
# Check API server metricsecho "=== API Server Metrics ==="kubectl get --raw /metrics | grep apiserver_request_duration_seconds_count | head -20
# Check etcd healthecho "=== etcd Health ==="ETCDCTL_API=3 etcdctl \ --endpoints=https://127.0.0.1:2379 \ --cert=/etc/kubernetes/pki/etcd/peer.crt \ --key=/etc/kubernetes/pki/etcd/peer.key \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ endpoint health
# Check scheduler metricsecho "=== Scheduler Metrics ==="kubectl get --raw /metrics | grep scheduler_scheduling_duration_seconds
# Check eventsecho "=== Recent Events ==="kubectl get events --all-namespaces --sort-by='.lastTimestamp' | tail -20
# Check resource usageecho "=== Resource Usage ==="kubectl top pods --all-namespaces | head -20Best Practices and Production Patterns
Resource Management
Resource management ensures fair sharing of cluster resources and prevents any single tenant from consuming everything. ResourceQuotas limit aggregate resource consumption per namespace, while LimitRanges set defaults and bounds for individual objects. These work together to implement multi-tenancy and prevent resource exhaustion.
These examples show production-ready resource controls:
# Resource quotas and limitsapiVersion: v1kind: ResourceQuotametadata: name: compute-quota namespace: productionspec: hard: requests.cpu: "1000" requests.memory: 2000Gi limits.cpu: "2000" limits.memory: 4000Gi persistentvolumeclaims: "10" services.loadbalancers: "5" services.nodeports: "10"
---apiVersion: v1kind: LimitRangemetadata: name: mem-limit-range namespace: productionspec: limits: - default: memory: 512Mi cpu: 500m defaultRequest: memory: 256Mi cpu: 100m type: Container - max: storage: 10Gi type: PersistentVolumeClaimMulti-Tenancy
Multi-tenancy in Kubernetes requires multiple layers of isolation: namespaces for logical separation, RBAC for access control, NetworkPolicies for network isolation, and ResourceQuotas for resource limits. While Kubernetes doesn't provide hard multi-tenancy out of the box, these primitives can create reasonable isolation for most use cases.
This NetworkPolicy example shows how to isolate tenant namespaces:
# Namespace isolation with NetworkPolicyapiVersion: networking.k8s.io/v1kind: NetworkPolicymetadata: name: deny-cross-namespace namespace: tenant-aspec: podSelector: {} policyTypes: - Ingress - Egress ingress: - from: - podSelector: {} # Same namespace only egress: - to: - podSelector: {} # Same namespace only - to: - namespaceSelector: matchLabels: name: kube-system # Allow DNS ports: - protocol: UDP port: 53Disaster Recovery
Disaster recovery in Kubernetes centers on backing up etcd, which contains all cluster state. Regular snapshots of etcd enable cluster restoration after catastrophic failures. Additionally, backing up resource definitions provides a way to recreate applications. For true disaster recovery, consider multi-region clusters or cluster federation.
This script demonstrates backup and restore procedures:
#!/bin/bash# backup-restore.sh
# Backup etcdETCDCTL_API=3 etcdctl \ --endpoints=https://127.0.0.1:2379 \ --cert=/etc/kubernetes/pki/etcd/peer.crt \ --key=/etc/kubernetes/pki/etcd/peer.key \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ snapshot save /backup/etcd-snapshot-$(date +%Y%m%d-%H%M%S).db
# Backup critical resourceskubectl get all,cm,secret,ing,pvc,pv -A -o yaml > /backup/resources-$(date +%Y%m%d-%H%M%S).yaml
# Restore etcdETCDCTL_API=3 etcdctl \ snapshot restore /backup/etcd-snapshot.db \ --data-dir=/var/lib/etcd-restore \ --initial-cluster=etcd-1=https://10.0.1.10:2380 \ --initial-advertise-peer-urls=https://10.0.1.10:2380 \ --initial-cluster-token=etcd-cluster-1Conclusion
Kubernetes architecture is a masterpiece of distributed systems design. Every component is built with resilience, scalability, and extensibility in mind. The key principles that make Kubernetes successful:
- Declarative API: Describe desired state, not imperative commands
- Reconciliation Loops: Continuously drive actual state toward desired state
- Level-Triggered Logic: Idempotent operations safe to retry
- Eventual Consistency: Tolerate temporary inconsistencies
- Modular Architecture: Pluggable components and extensions
- Distributed Consensus: etcd provides consistent source of truth
Understanding these internals transforms you from a Kubernetes user to a Kubernetes engineer. You can now:
- Debug complex issues by understanding component interactions
- Optimize clusters for specific workloads
- Extend Kubernetes with custom controllers and schedulers
- Design applications that work with Kubernetes patterns, not against them
- Build platforms on top of Kubernetes primitives
The journey from kubectl apply to running containers involves dozens of components, thousands of lines of code, and elegant distributed systems patterns. Master these, and you master cloud-native infrastructure.
For hands-on learning, explore the Kubernetes source code, implement a custom controller, or build an operator.